
sed (“stream editor”) is a Unix utility that parses and transforms text, using a simple, compact programming language.
Substitution command
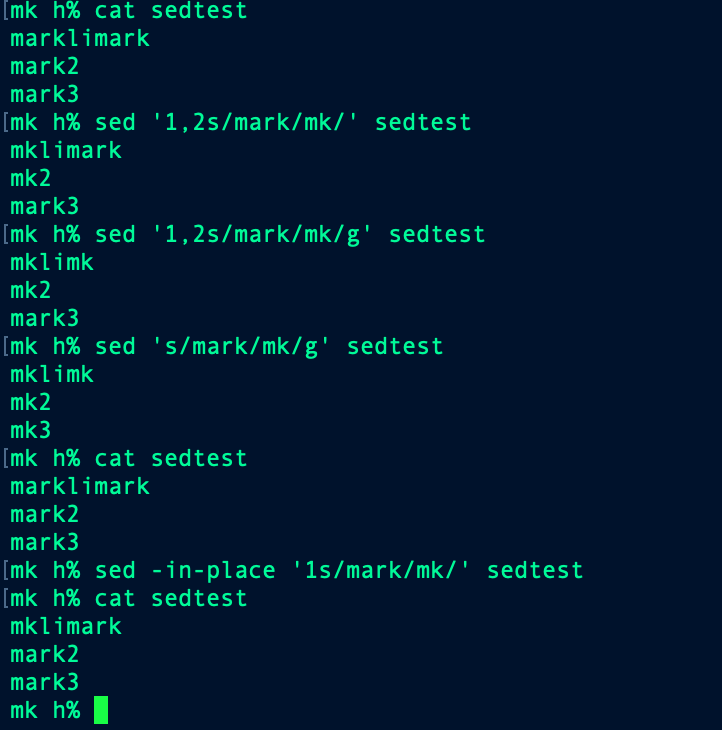
The s stands for substitute, while the g stands for global, which means that all matching occurrences in the line would be replaced.-in-place or -i:allows in-place editing of files (actually, a temporary output file is created in the background, and then the original file is replaced by the temporary file)
Other sed commands
The following uses the d command to delete lines that are either blank or only contain spaces:
sed '/^\s*$/d' sedtestsed 's/mark/mk/g; s/li//g' testfile Join two commands via the semicolon
sed '2,5d' testfile delete line 2~5
sed '3,$d' testfile delete line 3 to last linegrep
grep(globally search a regular expression and print)
grep -n '2019-10-24 00:01:11' *.log # Grep a log file within a specific time; -n:Display line numbers
grep -i 'rege[a-z]' file # -i:Ignore case
grep pattern -r dir/ # Recursion searchawk
awk, being the most powerful of these tools, is a scripting language that offers a multitude of features that do not exists in the former two.
awk '{print $1, $4}' log.txt # print the 1st and 4th column; by default, awk handles white spaces as a delimiter.
awk -F "," '{print $1, $4}' log.txt # we can specify it with the flag -F
awk -F '[ ,]' '{print $1, $4}' log.txt # Specify both space and comma as delimiter
awk '{printf "%-8s %-10s\n",$1,$4}' log.txt # make an aligned table
awk 'NR>1' log.txt # Filter out 1st line
awk 'NR==2 {print $1,$3,NR}' log.txt # Get the 2nd line of log.txt and print the 1st and 3rd column and line Number
awk '/ERROR/{print $1,$3}' log.txt # Find the regex pattern ERROR in the log.txt file and print the 1st and 3rd columnFor pipe stream
tail -f x.log | grep pattern