现在iPhone手机用户可以在input里输入一个emoji表情字符,但保存在数据库中发现是01二进制字符串,到底是什么原因呢?这与数据库设设置的支持的编码范围有关。
码表定义的历史:ASCII编码到Unicode到UTF-8
最初计算机只在美国用,他们决定用8个可以开合的晶体管来组合成不同的状态(00~FF) – 1字节(Byte) 256种状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的用途,一但终端、打印机遇上约定好的这些字节被传过来时,就要做一些约定的动作:
遇上0×10, 终端就换行;
遇上0×07, 终端就向人们嘟嘟叫;
遇上0x1b, 打印机就打印反白的字,或者终端就用彩色显示字母
他们看到这样很好,于是就把这些0×20以下的字节状态称为”控制码“
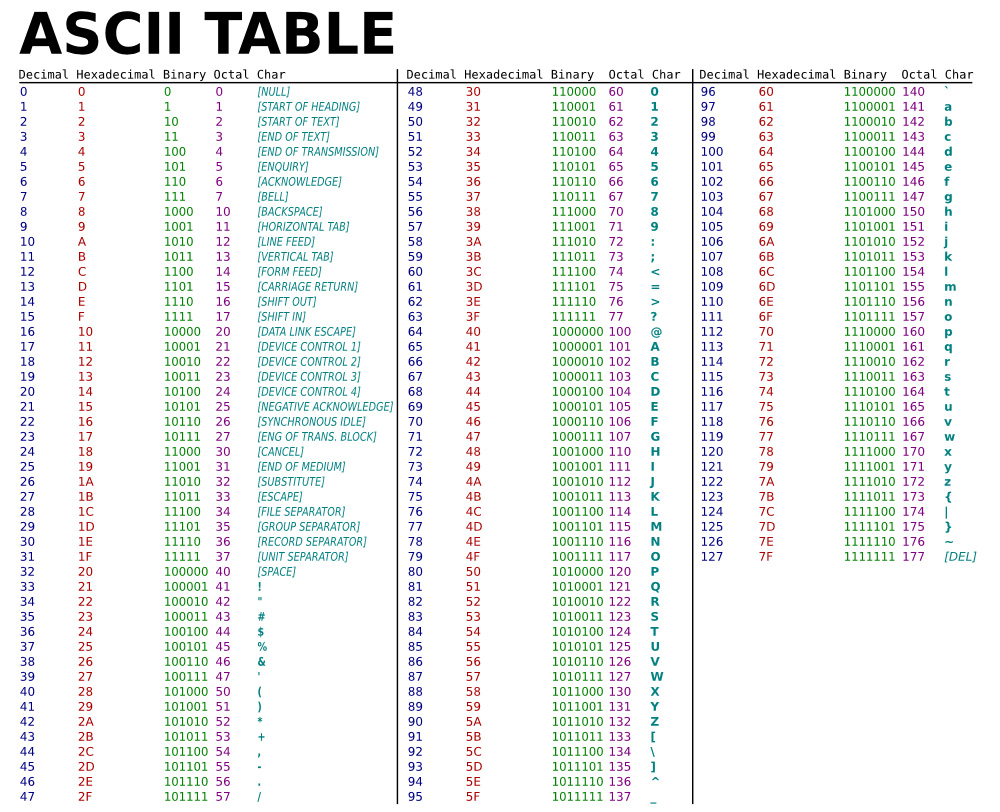
他们又把所有的空格、标点符号、数字、大小写字母分别用连续的字节状态表示,一直编到了第127号,这样计算机就可以用不同字节来存储英语的文字了。
American Nacional Standards Institute (ANSI)把这个方案叫做 ASCII 编码(American Standard Code for Information Interchange,美国信息互换标准代码)
当时世界上所有的计算机都用同样的ASCII方案来保存英文文字

后来,就像建造巴比伦塔一样,世界各地都开始使用计算机,但很多国家用的不是英文,为了可以用计算机保存他们的文字,他们决定采用127号之后的空位来表示这些新的字母符号,主要是欧洲国家-法语的变音(àêéèùüÉ),德语(ÄäÖöÜüß)等,希腊字母(αβγ),还加入了很多画表格时需要用到的横线、竖线、交叉等形状,一直把序号编到了最后一个状态255。从128到255这一页的字符集被称”扩展字符集“。
到中国开始使用计算机时,没有可以利用的字节状态来表示汉字,而且有6000多个常用汉字需要保存。然后设计了GB2312编码,规定:
一个小于127的字符的意义与ASCII编码相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。
在这些编码里,我们还把数学符号、罗马希腊的字母、日文的假名们都编进去了,连在 ASCII 里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角“字符,而原来在127号以下的那些就叫”半角“字符了。
GB2312 是对 ASCII 的中文扩展。
但是中国的汉字太多,于是我们不得不继续把GB2312 没有用到的码位也用上。后来还是不够用,于是干脆不再要求低字节一定是127号之后的内码,只要第一个字节是大于127就固定表示这是一个汉字的开始,不管后面跟的是不是扩展字符集里的内容。结果扩展之后的编码方案被称为 GBK 标准,GBK包括了GB2312 的所有内容,同时又增加了近20000个新的汉字(包括繁体字)和符号。
后来少数民族也要用电脑了,于是我们再扩展,又加了几千个新的少数民族的字,GBK扩成了 GB18030。
因为当时各个国家都像中国这样搞出一套自己的编码标准,结果互相之间谁也不懂谁的编码,谁也不支持别人的编码,连大陆和台湾这样只相隔了150海里,使用着同一种语言的兄弟地区,台湾的愚昧封建人士写的算命程式就必须加装另一套支持 BIG5 编码的什么”倚天汉字系统”才可以用,否则就显示乱码!真是计算机的巴比伦塔命题啊!
一个叫 ISO的国际组织决定着手解决这个问题。他们采用的方法很简单:废了所有的地区性编码方案,重新搞一个包括了地球上所有文化、所有字母和符号 的编码!叫它”Universal Multiple-Octet Coded Character Set”,简称 UCS, 俗称 unicode。
于是 ISO 就直接规定必须用两个字节,也就是16位来统一表示所有的字符,对于ASCII里的那些“半角”字符,unicode包持其原编码不变,只是将其长度由原来的8位扩展为16位,而其他文化和语言的字符则全部重新统一编码。由于”半角”英文符号只需要用到低8位,所以其高8位永远是0,因此这种大气的方案在保存英文文本时会多浪费一倍的空间。这对于英文国家是极大的空间浪费
unicode在很长一段时间内无法推广,直到互联网的出现,为解决unicode如何在网络上传输的问题,于是面向传输的众多 UTF(UCS Transfer Format)标准出现了,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。UTF-8就是在互联网上使用最广的一种unicode的实现方式,这是为传输而设计的编码,并使编码无国界,这样就可以显示全世界上所有文化的字符了。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用1个字节表示,注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节)。从unicode到UTF-8并不是直接的对应,而是要过一些算法和规则来转换。
为什么国内还有这么多使用 GBK 等编码的人?因为 UTF-8要用3个字节表示汉字,而GBK只需2个字节,如果面向的使用人群绝大部分都是中国人,用 GBK 等编码也可以
Reference
https://www.zhihu.com/question/23374078
操作系统应用程序文字编码
在非Unicode环境下,由于不同国家和地区采用的字符集不一致,很可能出现无法正常显示所有字符的情况。微软公司使用了代码页(Codepage)转换表(内码表)的技术来过渡性的部分解决这一问题,即通过指定的转换表将非Unicode的字符编码转换为同一字符对应的系统内部使用的Unicode编码,图形端再通过Unicode码渲染出来
cp936 — 即code page 936,是以GBK为基础的编码,大陆中文简繁体等
cp437 — 最初的IBM PC代码页,实现了扩展ASCII字符集
cp932 — 日文
cp949 — 韩文
cp950 — 繁体中文(big5)
cp65001 — UTF-8 Unicode
比如以前的游戏《轩辕剑》,台湾版程式安装在大陆版的PC上会出现乱码,因为台湾用的Big5编码,用大陆操作系统默认的GBK也可能是utf-8解码,自然乱码显示
可以在“语言与区域设置”中选择一个代码页作为非 Unicode 编码所采用的默认编码方式,而将代码页设置为相应语言,常规中文处理又会出现问题,当时玩这个游戏时,切换到big5,结果其它程序都变成乱码了。从根本上说,完全采用统一编码才是解决之道,但是Windows操作系统由于历史遗留原因尚无法做到这一点。
文本编辑器
我们将文字用各种不同的编码方式保存为二进制(文本文件),并以相应的解码方式调用图形接口渲染出来,机器会根据不同的硬件风格及字体等style渲染成不同的图像
不同操作系统对于换行的编码是不一样的

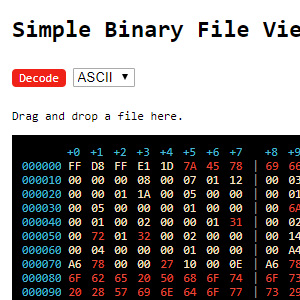
在线二进制解码器,使用UTF-8解码方式
在代码中对于换行这种非文字的东西只能用转义字符表示
UNIX/Linux:\n
Mac:\r
Windows:\r\n
所以在Linux系统上编辑的文件,本来是多行,在windows系统上的文本文件查看器(notepad)打开发现是一行,windows对于\n是不换行显示的(当然, 如果你Windows上的编辑显示器够智能, 如gvim, 那就是另外一回事了)
同样,你在windows下用notepad编辑的文件,在Linux系统上打开,会发现出现^M在尾部,并多出一空白行
如果你用vim编辑代码发布到linux服务器中,一定要选择UNIX方式存储数据,当然用windows自带notepad打开是不换行的
UTF-8 JavaScript编码算法
RFC2044文档(http: //www.ietf.org/rfc/rfc2044.txt?number=2044)描述了如何从一个内码转换成utf8格式的算法。
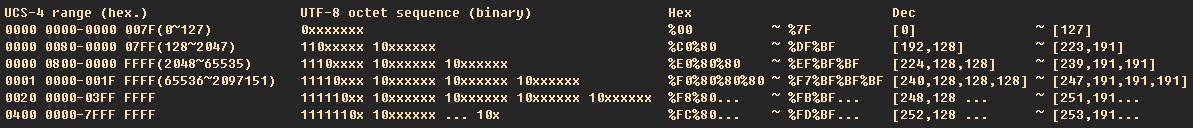
Javascript解码
‘搬’.charCodeAt(0) 返回字符串第一个字符的Unicode编码
/**
* encodeUtf8("我")
* [230, 136, 145]
*/
function encodeUtf8(text) {
const code = encodeURIComponent(text);
const bytes = [];
for (var i = 0; i < code.length; i++) {
const c = code.charAt(i);
if (c === '%') {
const hex = code.charAt(i + 1) + code.charAt(i + 2);
const hexVal = parseInt(hex, 16);
bytes.push(hexVal);
i += 2;
} else bytes.push(c.charCodeAt(0));
}
return bytes;
}
/**
* decodeUtf8([230, 136, 145])
* "我"
*/
function decodeUtf8(bytes) {
var encoded = "";
var len = bytes.length;
switch(len) {
case 0: return false; break;
case 1: if(bytes[0]>127) return false; break;
case 2: if(bytes[0]<194||bytes[0]>223||bytes[1]<128||bytes[1]>191) return false; break; // 实际上decodeURI支持的是始于[194,128]
case 3: if(bytes[0]<224||bytes[0]>239||bytes[1]<128||bytes[1]>191||bytes[2]<128||bytes[2]>191) return false; break;
case 4: if(bytes[0]<240||bytes[0]>247||bytes[1]<128||bytes[1]>191||bytes[2]<128||bytes[2]>191||bytes[3]<128||bytes[3]>191) return false; break;
case 5: if(bytes[0]<248||bytes[0]>251||bytes[1]<128||bytes[1]>191||bytes[2]<128||bytes[2]>191||bytes[3]<128||bytes[3]>191||bytes[4]<128||bytes[4]>191) return false; break;
case 6: if(bytes[0]<252||bytes[0]>253||bytes[1]<128||bytes[1]>191||bytes[2]<128||bytes[2]>191||bytes[3]<128||bytes[3]>191||bytes[4]<128||bytes[4]>191||bytes[5]<128||bytes[5]>191) return false; break;
default: return false;
}
for (var i = 0; i < len; i++) {
encoded += '%' +(bytes[i]<16?"0":"")+ bytes[i].toString(16);
}
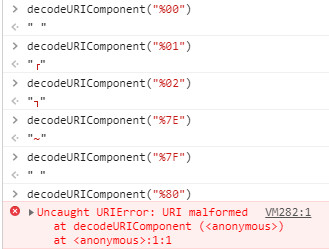
return decodeURIComponent(encoded);
}虽然escape()、encodeURI()、encodeURIComponent()三种在用法上差不多。但后两者是将字符串转换为UTF-8的方式来传输,解决了页面编码不一至导致的乱码问题。例如:发送页与接受页的编码格式(Charset)不一致(假设发送页面是GB2312而接收页面编码是UTF-8),使用escape()转换传输中文字串就会出现乱码
- encodeURI和encodeURIComponent都不会转义 A到z,0到9,以及-_.!~*'()
- encodeURI不会转义 ;/?:@&=+$#这11个字符但encodeURIComponent会,这是这两者的区别
- escape不会转义A到z, 0到9, _.*/@+- 会转义!~'();?:&=$#
- 其它上面没提到的字符,汉字啊,都会被encodeURI和,encodeURIComponent和escape转义
escape(",")
> "%2C"
encodeURI(",")
> ","
encodeURIComponent(",")
> "%2C"
escape("我")
> "%u6211"
encodeURI("我")
> "%E6%88%91"
encodeURIComponent("我")
> "%E6%88%91"在线二进制解码器,其中有ASCII和UTF-8两种解码方式
emoji编码
UTF-8编码有可能是一个、两个、三个、四个字节。Emoji表情是4个字节,而Mysql的utf8编码最多3个字节,所以数据插不进去
查看Emoji Unicode 码表表中,另外同一个Emoji表情在不同操作系统下的字体不一样(Emoji样式由设置的字体决定)
可以修改数据库编码方式为utf8mb4, 比如wordpress 就由以前的utf8改成了utf8mb4, mb4的意思是most bytes 4
Mysql官方对utf8mb4的说明(http://dev.mysql.com/doc/refman/5.5/en/charset-unicode-utf8mb4.html)
utf8mb4与utf8mb3字符集相比:
对于BMP 字符, utf8mb4 和 utf8mb3 具有相同的存储特性:相同的code values, same encoding, same length.
对于补充字符,utf8mb4需要四个字节来存储它,而utf8mb3根本不能存储该字符。 将utf8mb3列转换为utf8mb4时,您不必担心转换补充字符,因为不需要转换。
所以utf8mb4并不会增加什么空间成本,但兼容性会更好一些