在教科书中,如果我们想阅读某个特定主题,我们只需搜索目录索引中给出的主题并找到它出现的相应页码。索引是将无序表按顺序排列的方法,这样可以在搜索时最大限度地提高查询效率。

索引字段会像字典一样排序
当表未编入索引时,查询必须搜索每一行才能找到符合条件的行。
例如,下表完全无序。
| COMPANY_ID | UNIT | UNIT_COST |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1.35 |
| 14 | 12 | 1.95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
如果我们要运行以下查询:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18数据库必须从上到下一次搜索所有 17 行找到company_id值为 18 的所有实例。
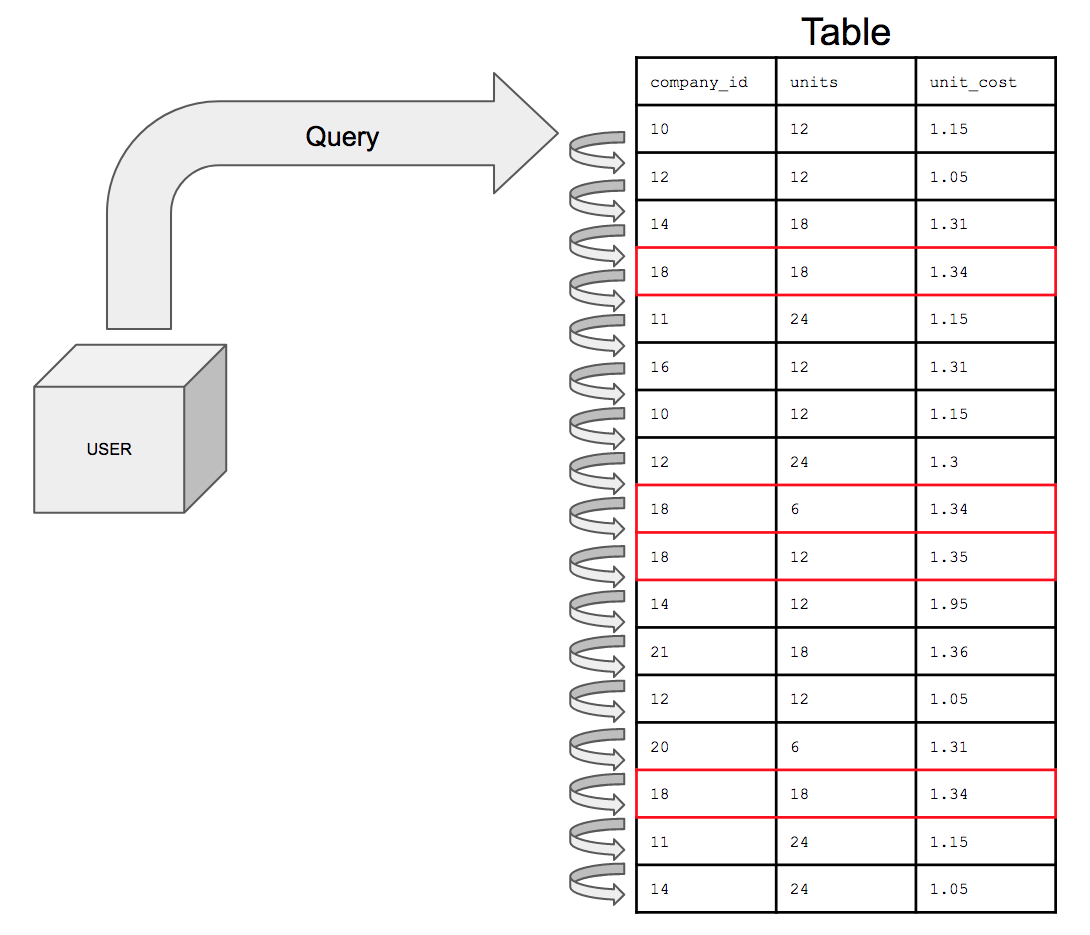
随着表的大小增加,这只会越来越耗时。随着数据复杂性的增加,最终可能发生的情况是一个 10 亿行的表与另一个 10 亿行的表相连;查询现在必须搜索两倍的行,花费两倍的时间。
索引的作用是按排序顺序设置搜索条件所在的列,以帮助优化查询性能。
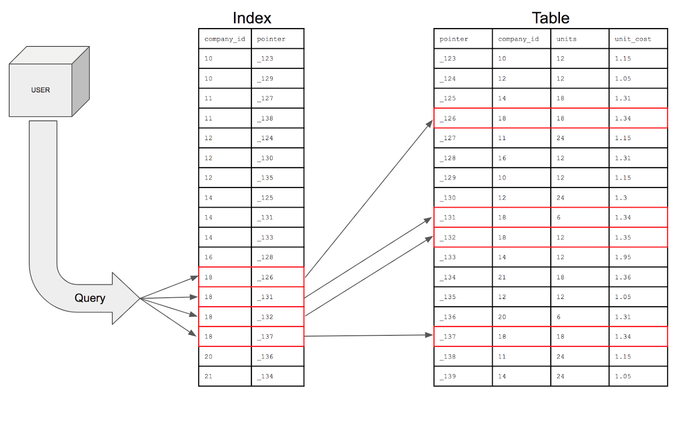
现在,数据库可以搜索company_id数字 18 并返回该行的所有列,然后移至下一行。如果下一行的company_id编号也是 18,那么它将返回查询中行的所有列。如果下一行company_id是 20,则查询知道停止搜索并且查询将完成。

显然,数据库会分配空间来创建存储索引的数据结构。数据结构类型很可能是B-Tree。当索引在特定列上创建数据结构时,重要的是要注意没有其他列存储在数据结构中。我们上表的数据结构将只包含company_id数字。units和unit_cost不会保存在数据结构中。数据库索引有存储指针,指针是包含其余信息的行在内存磁盘上的地址。
一个数据库表可以有一个或多个与之关联的索引。
索引太多也有缺点,数据变动,索引也需变动,比如再插入一个company_id 为 18的数据,上面的索引表就要改动,因此,索引会降低一些插入、更新和删除操作的性能。同样, 索引会占用额外的磁盘空间存放索引表。