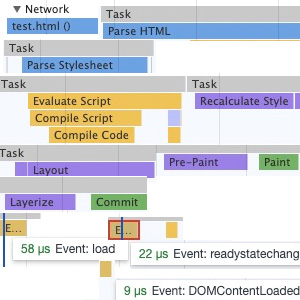
本文围绕浏览器工作流展开,利用Dev Tools 工具查看浏览器工作的各个阶段。
浏览器的构成
浏览器由以下几个部分组成:
* 用户界面 - 它包括地址栏, 后退/前进按钮, 书签菜单等. 浏览器的除请求到的页面内容窗口之外的每一个部件的显示 * 浏览器引擎 - 查询并操纵渲染引擎的接口 * 渲染引擎 - 负责显示请求的内容. 例如如果请求的内容是HTML, 它负责词法分析HTML和CSS并在屏幕上显示词法分析后的内容,有时它需要通过插件(浏览器扩展)的方式渲染显示其它类型,如PDF要使用PDF viewer plug-in。Safari和Chrome使用Webkit,Firefox使用Gecko。 * Networking - 请求网络, 如HTTP请求 * UI后端 - 用于绘画基本部件像组合boxes和windows. * JavaScript 解析器. 用于词法分析并执行JavaScript代码,包含GC(内存回收) * 数据存储.这是一个持久的层. 浏览器需要保存各种数据在硬盘上.例如cookies. 新的HTML5标准定义了'web database'是浏览器中的一个完整(尽管轻量)的数据库
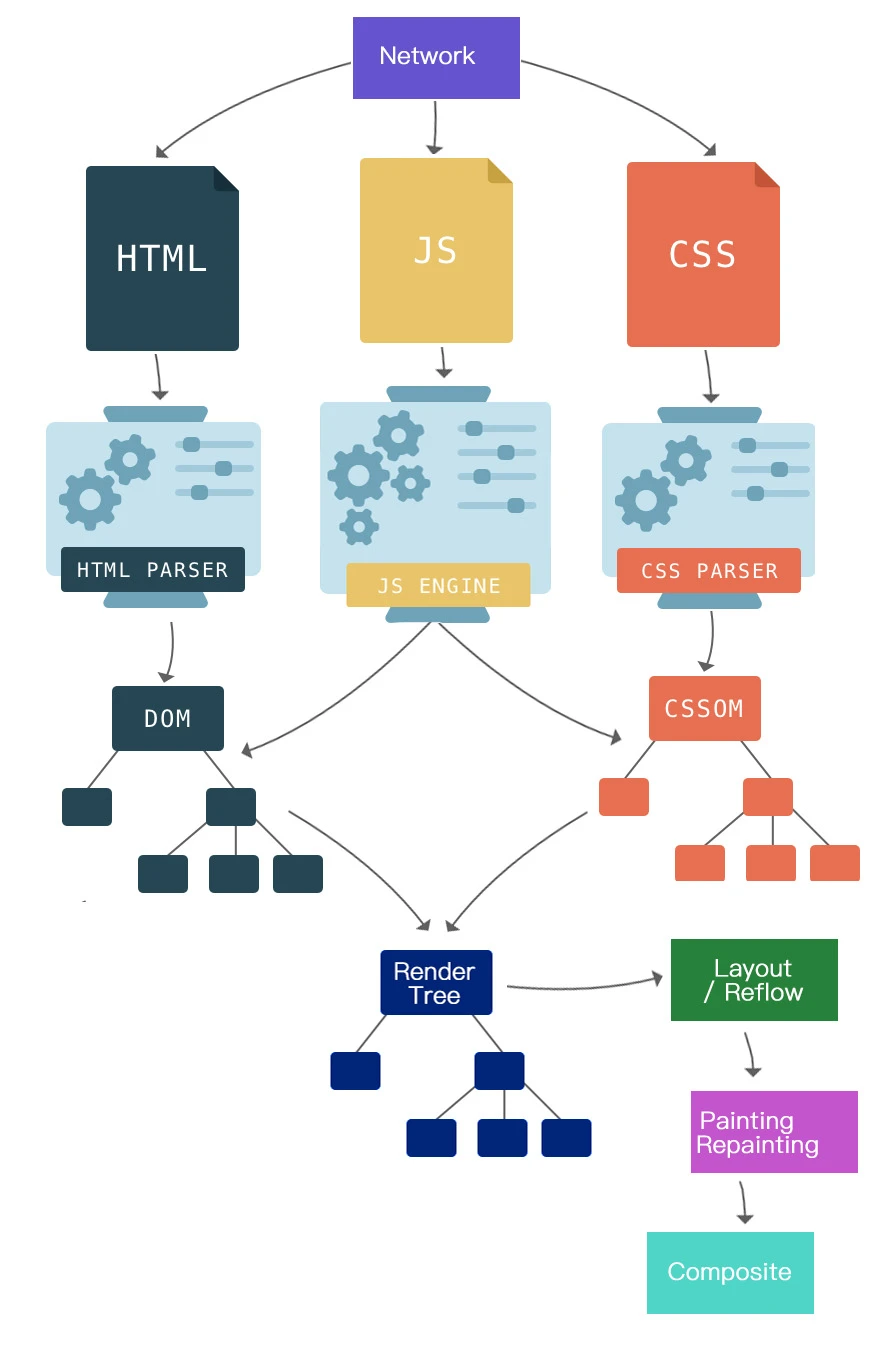
网络
DNS 解析, 浏览器有DNS 缓存,会先去查缓存,另外还有一种安全的解析服务,就是DoH ,通过HTTPS 协议获得 IP 而不是明文的 DNS 协议获得目标域名的 IP。
HTTP 请求基于TCP, HTTP3 基于UDP。
HTTPS 基于 TLS, 通过非对称加密获得浏览器端生成的随机密钥,然后用此随机密钥以对称加密来和服务器通信。
构建 DOM 和 CSSOM
渲染引擎使用 HTML Parser(词法分析器)构建DOM 树,使用CSS Parser 构建CSSOM 树,并将它们存储在内存中。
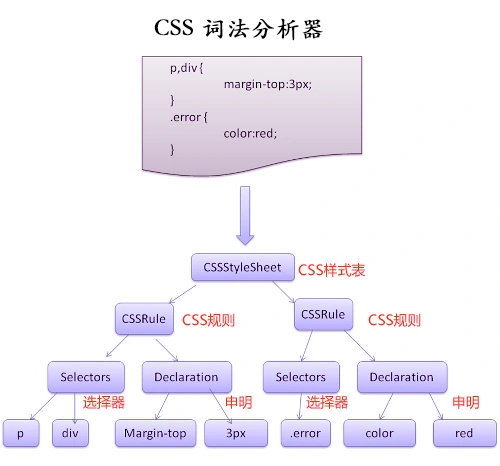
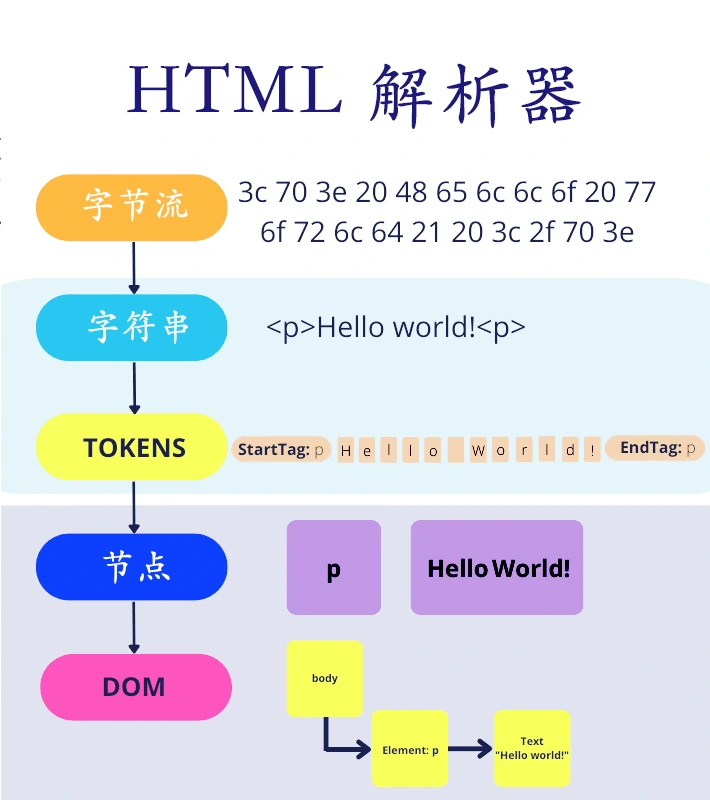
构建渲染树(Render Tree)
在开始渲染页面前,浏览器引擎会将 DOM 树和 CSSOM 树结合起来,形成一个 Render Tree,然后再根据 Render Tree 中的信息进行页面布局 Layout 和绘制 Paint。
浏览器将开始从DOM 树根结点开始遍历每个可见节点。一些节点,如script 标签或meta 标签是不可见的,因此构建渲染树时会忽略掉它们。还有一些节点通过使用 CSS(display: “none”例如属性)隐藏,它们也将被忽略。
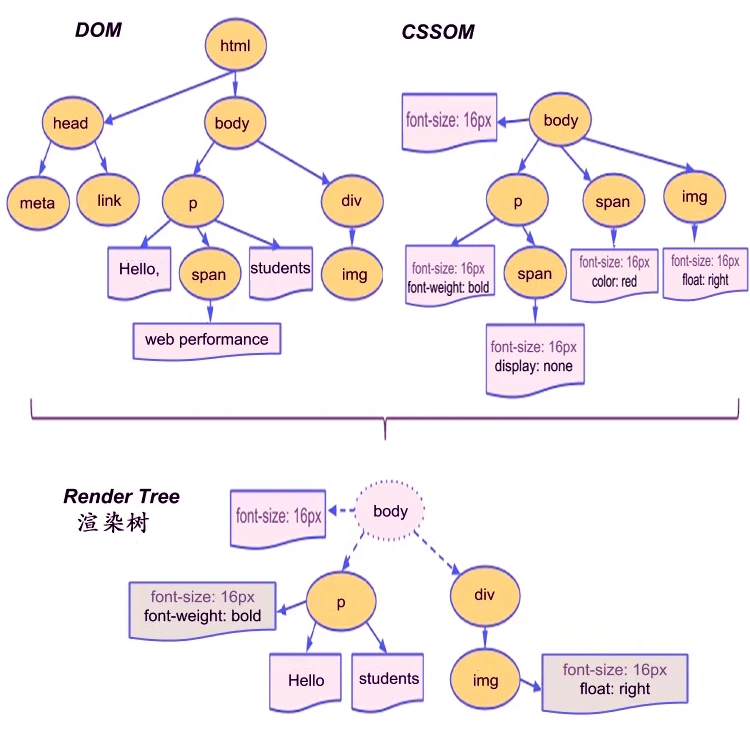
渲染树包含要显示哪些结点,及计算样式的信息,但不包含每个节点的尺寸和位置。
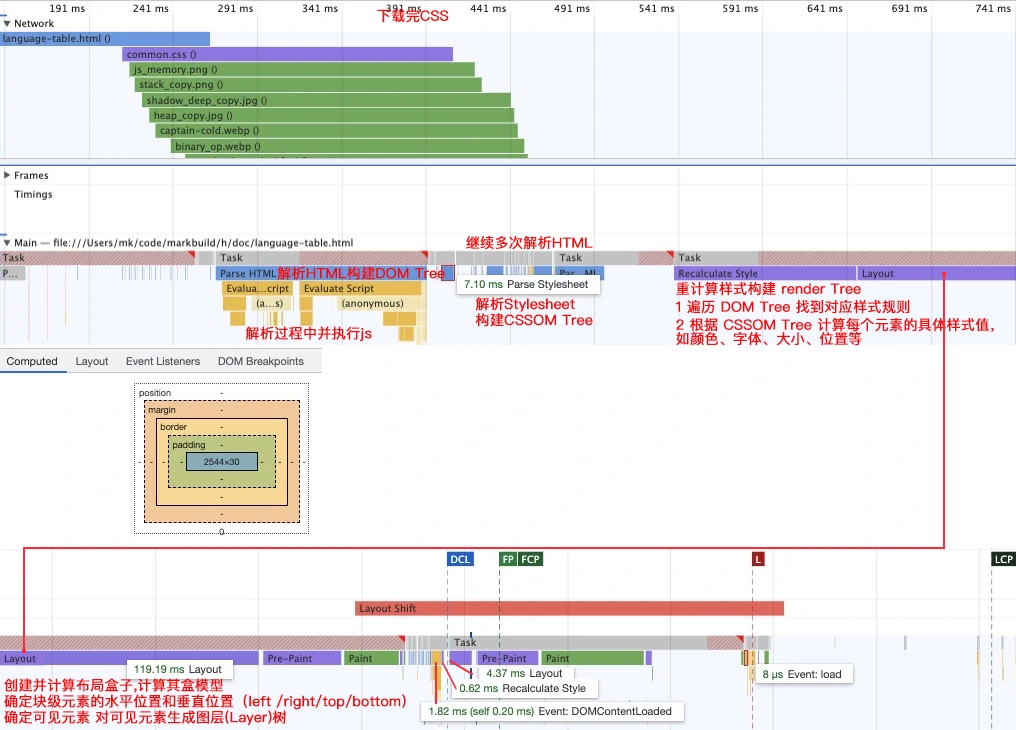
布局(Layout )或回流(Reflow)
布局或回流要做事情就是计算出每个元素的尺寸和位置,创建元素的盒模型。
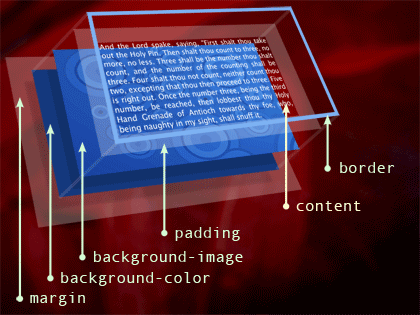
布局或回流通常不会只发生一次,当节点删除新增,窗口大小调整,内容长度变化就会重新计算每个节点的尺寸和位置。
绘画(Painting)或重绘(Repainting)
这个阶段负责在屏幕上渲染像素。
绘画或重绘通常不会只发生一次,当改变元素颜色,背景,滚动页面,改变元素透明度等就需要重新渲染像素。
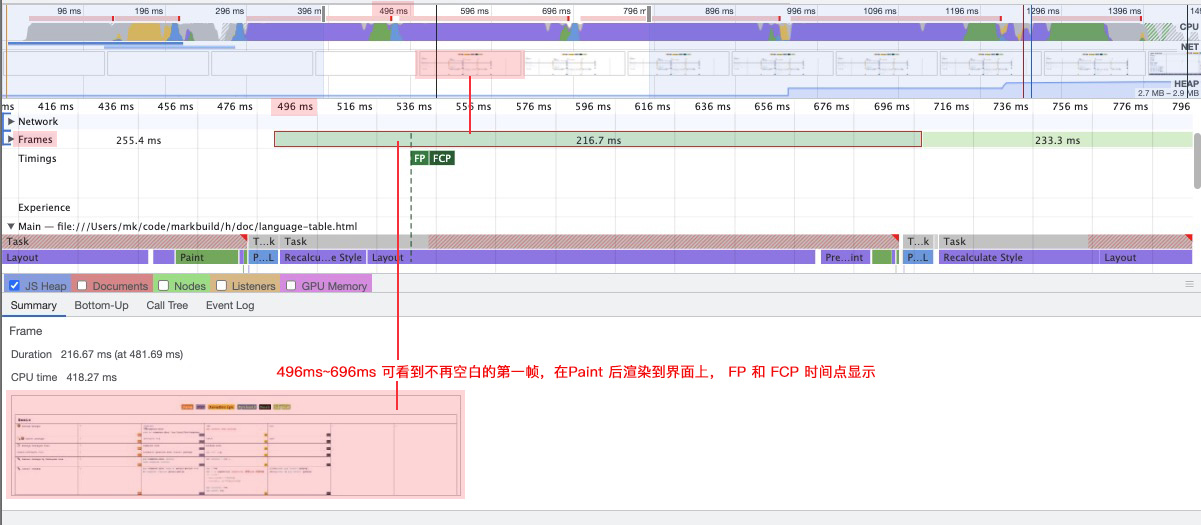
Reflow 的代价比 Repainting 大很多,所以要避免触发 Reflow。
为了让重绘比初始化绘制更快的完成,通常会将屏幕上的绘图分解成几层,然后合成。
commit 是将之前的 Layout、Paint 的结果绘制到页面上,即生成一个由多个图层(Layer)组成的位图(Bitmap),该阶段还会生成一个 DisplayList,并将其提交给浏览器进程的渲染器线程(Renderer Thread)。
分层(Layer)和合成(Composite)
Composite 阶段是将不同的图层组合成最终的位图,并将其显示在屏幕上。这一阶段是在浏览器进程的 Compositor 线程中完成的,而不是在渲染器线程中。在这个过程中,每个图层会根据其在页面中的位置、层级关系和透明度等属性进行合成,生成最终的画面。最终的位图就是在 Composite 阶段生成的。
传统浏览器通常完全依赖 CPU 来呈现页面内容,随着硬件性能的提高,现在逐渐考虑将一些任务交给 GPU 来处理了。
为了找出哪些元素在哪一层,主线程遍历布局树并创建 Layer Tree。默认情况下只有一层,但我们可以找到触发重绘元素并为每个元素创建单独的层,这样,重绘不应应用整个产面,此过程可以使用 GPU