在做LED广告编辑器时,需要用HTML5 Canvas来渲染GIF格式,Canvas只能取得GIF的第一帧,要想获得GIF这种动态图的每一帧,可以从内存中读取二进制,并解码,获得每一帧的图像数据。
GIF结构
GIF 文件由一大堆不同的数据块组成。
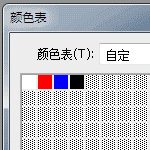
这是一个10px * 10px 的案例gif文件

放大10倍后仔细看是这样的


GIF 是一种位图图片编码格式,他用到了颜色索引表。
这样我们在编码时记录每个像素颜色值时,记录的是颜色的索引值(index),而不是颜色本身的那个值,颜色本身的值,不透明的就要占用 3 个节点(比如白色6个F),而这种使用颜色索引表的格式是一个有损压缩,损的就是这个图片上的颜色总数,最多256种颜色,它挑选最有代表性的颜色做这个颜色表。256个种颜色,一个字节就可储所有的索引值。也就是现在我们只需要 1 个字节存这个颜色。容量就是原来 3 个字节的 1/3 。
GIF 和 PNG-8(8位色深,不支持透明和全彩色)都用到索引颜色,而JPEG 和 PNG-24 没有索引颜色。
上面案例 gif 的图像数据应该存储这些索引值
1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, …
这些值存储在GIF文件的 Image Data 区块,而GIF的文件总体格式是这样的

Header 区块
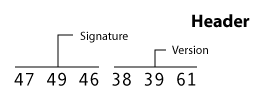
所有 GIF 文件必须以Header 区块开头,它占用6个bytes,由签名(signature)+ 版本组成。
头三个字节是签名。它应该一直是”GIF” (ie 47=”G”, 49=”I”, 46=”F”)。
后三个字节规范版本。 我们只会使用“89a”(即38 =“8”,39 =“9”,61 =“a”)。 唯一其它认可的版本是“87a”。
Logical Screen Descriptor 逻辑屏幕描述符区块
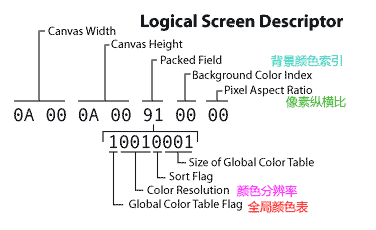
头2个字节代表画布宽(值的范围 0 ~256*256-1=65535)
在GIF格式中,多字节值会先储存低位字节(LITTLE-ENDIAN), 即低位字节排放在内存的低地址端,高位字节排放在内存的高地址端)
也就是我们会从 byte 流中读取0A00, 实际代表的值是000A。 所以上图的宽是10像素。同理255会存储为FF00 而 256 会存储为 0001。
接着2个字节代表画布高。
第5个字节(0x91)是一个Packed字节,字节91可以表示为二进制数10010001 。
第1个比特(bit)是全局颜色表 Flag 。如果值是0,后面就没有颜色表,如果是1就有颜色表。
接下来三位表示颜色分辨率, 001表示 2 bits/像素, 111 表示8 bits/像素,如果是256种颜色的颜色表,就要用8 bits。
后一位是排序标识,如果值为1,那么颜色在全局颜色表中以”decreasing importance”来排序, 它在图像中意味着”decreasing frequency”.这可以帮助图像解码器,但不是必需的。
最后三位是全局颜色表的大小,它的值是2^(1+n),上面n为1,所以颜色表的大小是2^(1+1)=4,n的最大值111(十进制7),所以颜色表的数目范围是(2/4/8/16/32/64/128/256)
第6个字节是背景颜色索引值,这个字节在全局颜色表flag值为1时,即有全局颜色表时才有用。它通过这个索引值在全局颜色表中找到对应颜色作为背景色。
如果没有颜色表,这个值为0.
第7个字节是像素纵横比
Global Color Table 区块

每种颜色都以3个字节(RGB)存储,前面我们知道上面GIF的颜色表大小是2^(1+1)=4,那么这个图的颜色表需要占用3*4=12个字节,0xFF 0xFF 0xFF 0xFF 0x00 0x00 0x00 0x00 0xFF 0x00 0x00 0x00, 即白(#FFFFFF)红(#FF0000) 蓝(#0000FF) 黑(#000000)
Graphics Control Extension 图形控制扩展
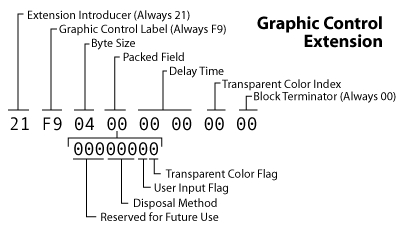
图形控制扩展块经常用于指定透明度设置和控制动画。
第1个字节是扩展引导器,所有扩展块以21开头。
接下来是图形控制标签F9,用来说明这是一个graphic control extension。
第3个字节是Byte Size,它的值总是4.
第4个字节是packed field.
Bits 1-3是预留未来用的,值都是0.
Bits 4-6表示处置方法,三位可以代表0~7之间的数字. 值1告诉解码器保留此帧图像,并在它的基础上画下一个图像.值2代表画布应该恢复为背景颜色(如Logical Screen Descriptor中所示).值3代表解码器需要restore the canvas to its previous state before the current image was drawn. 值4-7还未定义,如果图像不是多帧动画,那么值为0.
Bit 7是用户输入标志,当为1时代码解码器 will wait for some sort of “input” from the person viewing the image before moving on to the next scene. I’m guessing it’s highly unlikely that you will encounter any other value that 0 for this bit.
Bit 8是透明颜色标志,如果没有使用透明度,则为0,有则为1.
第5,6个字节是延迟时间值,实际时间为此值乘以0.01s
第7个字节是透明颜色索引,GIF没有半透明,如果一个图像的颜色索引是255,颜色表中索引255的颜色值是rgb(255,255,255),那么Image Data中存储255索引的像素最终在图像上的值就是rgba(255,255,255,0);
最后一个字节是block终结者,它的值总是00.
Image Descriptor 区块
数据流中的每个图像都由一个图像描述符,可选的局部颜色表和图像数据组成。图像描述符可能跟在一个或多个控制区块(如Graphic Control Extension)后面
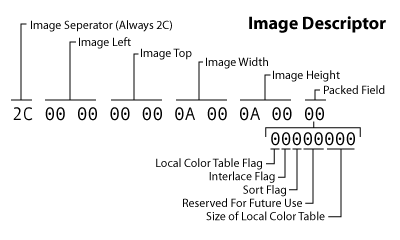
一个GIF文件可能包含多个图像帧,也就是动画。每一个图像帧都以一个图像描述符开始。这个block占10个字节。
第一个字节是图像分隔符。每个图像描述符以0x2C开头.接下来8个字节表示图像位置和尺寸。图像不一定占据logical screen descriptor定义的整个画布。因此就有left和top属性。
最后一个字节也是一个packed field.第一位是局部颜色表.如果设置为1允许你指定局部颜色表。
Image Data
上面案例gif的图像数据应该存储这些索引值
1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, …
但这样直接存储会生成一个较大的GIF文件,GIF是会压缩这个的。
通过压缩方式,实际存储的格式是这样的。
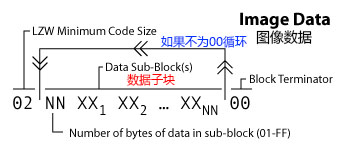
LZW 压缩算法
这里是GIF 版的 LZW 压缩,它和标准 LZW 压缩算法有点差别,它会创建一个编码表,编码表允许你使用编码(Code)来表示一串颜色索引值,而不是每次一个颜色索引值
首先初始化编码表,将颜色表中的每一个索引(Index)值分配一个编码。如果有局部颜色表则使用局部颜色表,否则使用全局颜色表。 (为了区分,给编码添加了一个 “#” 来区别颜色索引)
| Code | Color(s) |
|---|---|
| #0 | 0 |
| #1 | 1 |
| #2 | 2 |
| #3 | 3 |
| #4 | Clear Code |
| #5 | End Of Information Code |
有两个特殊编码(仅用于GIF版的LZW, 标准LZW压缩没有的):Clear code(CC)用来提示重新初始化编码表。End Of Information Code(EOI),提示已到达的图像的未尾了。
特殊编码紧跟颜色编码之后,实际上特殊编码的编码值取决于LZW最小编码长度.
如果LZW最小编码长度与颜色表的大小相同,那么特殊编码会紧跟颜色编码后面,比如上面#3 后面的特殊编码以#4 开始;如果定义了一个较大的LZW最小编码长度值,特殊编码与最大颜色编码间会存在间隔。
| LWZ Min Code Size | Color Codes | Clear Code | EOI Code |
|---|---|---|---|
| 2 | #0~#3 | #4 | #5 |
| 3 | #0~#7 | #8 | #9 |
| 4 | #0~#15 | #16 | #17 |
| 5 | #0~#31 | #32 | #33 |
| 6 | #0~#63 | #64 | #65 |
| 7 | #0~#127 | #128 | #129 |
| 8 | #0~#255 | #256 | #257 |
接下来定义两个术语:索引流(index stream)是每个像素点上颜色索引值的队列,也是我们将要压缩的值。编码流(code steam)是我们要生成的编码值的队列。
现在我们开始步入LZW压缩算法.
- 初始化编码表
- 始终从发送一个Clear Code到编码流开始
- 读索引流的第一个索引值,现在这个索引值赋值为索引缓冲区的值
- 循环点
- 从索引流获得下一个索引值, 赋值给 K
- (索引缓冲区的值 + K值) 是否在编码表中?
- 在:
- 添加K值追加给索引缓冲区并清除 K 值
- 如果还没到索引流的未端, 返回循环点
- 不在:
- 将(索引缓冲区的值 + K值) 追加一行到编码表,跟在 EOI 编码后
- 输出索引缓冲区中的值的编码到编码流
- 重置索引缓冲区的值为 K值
- 清除K值
- 如果没还到索引流的未端, 返回循环点
- 输出索引缓冲区的值的编码到编码流
- 输出EOI code
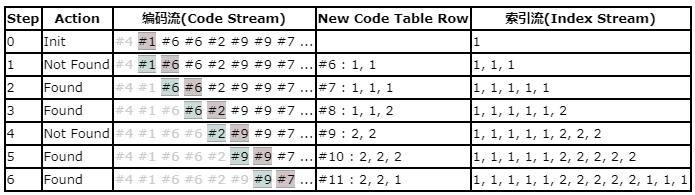
[Step 0] 现在以我们的例图来走一遍上面的流程. (下表中描述了每一步的数据变化.加绿背景的数字代表处在索引缓冲区;加紫背景的数字是当前的K值)
[Step 0]我们已经初始化了编码表.首先输出clear code (#4)到编码流,并从索引流中读取第一个颜色索引值 1, 到我们的索引缓冲区.
[Step 1] 现在我们进入算法的主要循环部分。从索引流中读取下一个索引值 1, 附值给 K.
[Step 2] 现在我们要看是否(索引缓冲区的值 + k值)在我们的编码表中。这个例子中我们就要查找(1,1). 当前的编码表只包含单颜色索引值,所以这个值不存在。现在就需要在编码表中追加新的一行,来存储这个(1,1)值,下一个可用的编码是 #6, 那么就让#6值为 (1,1)。记住我们并没有发送这个编码到编码流, 而是发送索引缓冲区中值1的编码 #1 到编码流.
现在我们重置索引缓冲区的值为K值,清除K值。
[Step 3] 继续读下一个索引值,附值给 K。
[Step 4] 现在 K 值是 1 索引缓冲区的值是 1,这次索引缓冲区的值 + k值 (1,1) 存在在编码表中,因此我们添加 K 值追加给索引缓冲区,并清除K值 。 现在索引缓冲区的值为(1,1)。
[Step 5] 继续读下一个索引值,还是 1 附值给 K。
[Step 6] 现在(索引缓冲区的值 + k值)为(1,1,1),在我们的编码表中是没有的 。同之前的操作一样,在编码表中尾随添加新的一行,来存储这个(1,1,1)。下一个编码号是#7, 让 #7 = (1, 1, 1)。现在将索引缓冲区值的编码 #6 送进编码流,并将索引缓冲区值的值设置为 k 值,清除K值。 [Step 6].
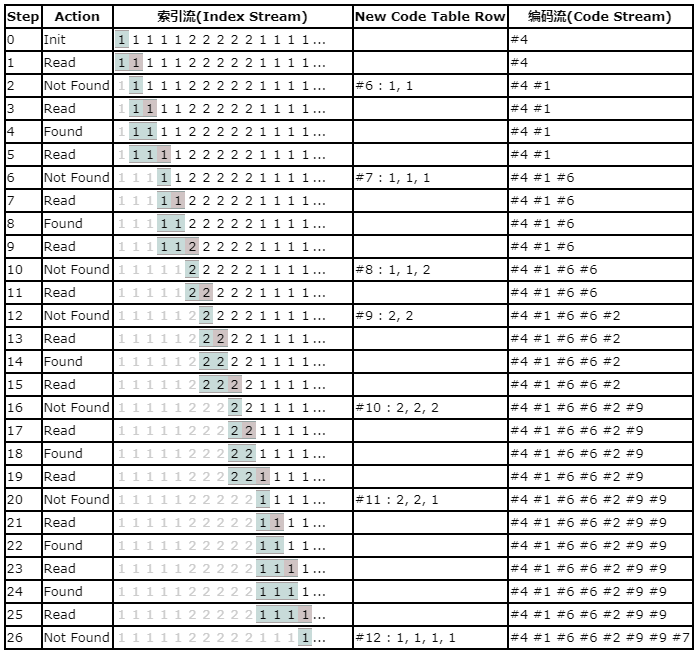
就这样直到分析完索引流所有的值。这是最后完整的编码表。
| Code | Color Index(es) |
|---|---|
| #0 | 0 |
| #1 | 1 |
| #2 | 2 |
| #3 | 3 |
| #4 | clear code |
| #5 | end of information code |
| #6 | 1, 1 |
| #7 | 1, 1, 1 |
| #8 | 1, 1, 2 |
| #9 | 2, 2 |
| #10 | 2, 2, 2 |
| #11 | 2, 2, 1 |
| #12 | 1, 1, 1, 1 |
| #13 | 1, 1, 2, 2 |
| #14 | 2, 2, 2, 2 |
| #15 | 2, 1 |
| #16 | 1, 1, 1, 1, 1 |
| #17 | 1, 2 |
| #18 | 2, 2, 2, 2, 2 |
| #19 | 2, 1, 1 |
| #20 | 1, 1, 0 |
| #21 | 0, 0 |
| #22 | 0, 0, 0 |
| #23 | 0 ,2 |
| #24 | 2, 2, 2, 1 |
| #25 | 1, 1, 1, 0 |
| #26 | 0, 0, 0, 0 |
| #27 | 0, 2, 2 |
| #28 | 2, 2, 2, 2, 2, 0 |
| #29 | 0, 0, 0, 0, 1 |
| #30 | 1, 1, 1, 2 |
| #31 | 2, 2, 2, 0 |
| #32 | 0, 0, 0, 0, 1, 1 |
| #33 | 1, 1, 2, 2, 2 |
| #34 | 2, 2, 2, 1, 1 |
| #35 | 1, 1, 1, 1, 2 |
| #36 | 2, 2, 2, 2, 2, 1 |
| #37 | 1, 1, 1, 1, 1, 2 |
| #38 | 2, 2, 2, 2, 2, 1, 1 |
对于大的GIF文件,可能会生成很大数目的编码表,但GIF定义的最大编码号是#4095 (12-bit number 0xFFF). 如果你想使用新的编码,则需要清除所有旧的编码,你可以发送clear code (例子中的#4).它将告诉解码器你将重新初始化你们的编码表. 然后你可紧跟EOI code重新构建编码行 (例子中,从#6 重新开始).
最后的编码流为:
#4 #1 #6 #6 #2 #9 #9 #7 #8 #10 #2 #12 #1 #14 #15 #6 #0 #21 #0 #10 #7 #22 #23 #18 #26 #7 #10 #29 #13 #24 #12 #18 #16 #36 #12 #5
这只有36个编码,而不压缩就要10*10=100个编码.
LZW解压缩算法
如何将编码流解码成索引流,并跟据颜色表将对应的颜色吐到画布上.
首先定义几个术语:
CODE will be current code we’re working with。
CODE-1 will be the code just before CODE in the code stream。
{CODE} 是CODE在编码表中的值.例如上面压缩部分的编码表,如果 CODE=#7 那么 {CODE}=1,1,1.
- 初始化编码表
- 将编码流的第一个编码附值给CODE
- 输出 {CODE} 到索引流
- 循环点
- 从编码流获得下一个编码值附值给CODE
- CODE是否在编码表中?
- 在:
- 输出 {CODE} 到索引流
- 将{CODE}中的第一个索引附值给 K
- 添加 {CODE-1}+K 到编码表
- 不在:
- 将{CODE-1}中的第一个索引附值给 K
- 输出 {CODE-1}+K 到索引流
- 添加 {CODE-1}+K 到编码表
- 返回循环点
让我们来读编码流。编码流的第一个值是clear code.这意味着我们应该初始化我们的编码表.我们先得知道LZW最小编码长度(image data block的第一个值). 再次我们建立了一个编码#0-#3代表4种颜色加一个clear code (#4) 一个EOI code (#5)的编码表.
下一步是读第一个颜色编码.下面中紫背景的值是CODE值,绿背景的值是CODE-1值.第一个CODE值是#1.然后我们输出{#1}, 或1, 到索引流[Step 0].
现在我们进入算法的主要循环部分。下一个编码值是 #6. 它暂时不存在于编码表.那个我们就要将{CODE-1}的第一个索引值附值给 K. 因此 K = {#1}的第一个索引值 1. 现在将{CODE-1} + K即(1,1)输出到索引流并将(1,1) 尾随添加到编码表中. [Step 1].
继续读下一个编码. CODE现在是#6 并存在于编码表中.因此我们将输出{#6}即(1,1)到索引流. 现在我们将{#6}的第一个索引值1, 附值给 K. 在继续前进之前,我们需要添加{CODE-1}+K 到编码表.因此 #7 现在为(1, 1, 1) [Step 2].
按照这个流程走下去,你会发现,创建的编码表和压缩时创建的编码表是一样的,这就是LZW的伟大之处.
保存编码流为字节流
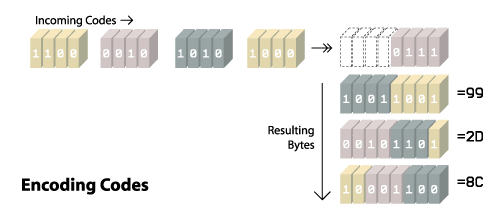
image data 由占1字节(8bits)代表LZW最小编码长度的值开头.GIF格式允许这个长度最小2bits最大12bits. 最小编码长度的值通常是 图像上每个像素上用来表示颜色索引值所占用的bits数. 所以如果你的图像中有32种颜色,你就需要每个像素占用5bits(00000~11111,0-31,共32种颜色).
有趣的是: 最小编码长度的值并不是编码过程中所使用的最小编码长度. 因为最小编码长度只是告诉你在图像中需要多少bits来表示不同颜色, 你还要计算两个必须加进编码表中的特殊编码(CC & EOI). 因此实际使用的最小编码长度要比定义的最小编码长度多一位. 我们称这个新的值初始编码长度.
当编码成编码流时,需在碰到添加编码值等于2^(当前编码长度)-1到编码表时,增加编码长度.
当解码成索引流时, 需在碰到添加编码值等于2^(当前编码长度)-1到编码表时,增加编码长度.
回到例图,最小编码长度是2,这意味着第一个编码长度应该占3bits.编码流的前4个编码#4 #1 #6 #6, 将会编码成110 001 110 和 110. 在上面编码的Step 10, 我们添加了一个#8到编码表.8等于2^3 (而3是当前编码长度),编码长度就要增加为4.因此,下一个编码#2, 将使用新的编码长度4 ,也就是要编码成 0010. 如下图:
在解码的过程中,我们再次增加编码长度when we read the code for #7 并读取下4个bits而不是3bits来获得下一个编码. In the sample table above this occurs in Step 2.
当你用完所有编码流中的编码,当最个一个不足填充8位凑成一个字节,那么就要把剩余的位填充为0. 图像数据必须分解成数据子块(sub-blocks)。每个数据子块以一个统计数据子块长度的字节开头.这个值在1~255(1字节)。
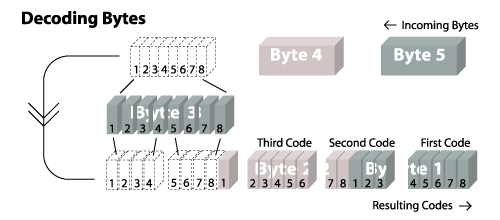
那如何将Byte流还原成编码流了
Return codes from bytes the basically just the same process in reverse. 下面的示例图能展示如何extract codes if the first code size were 5 bits.
Plain Text Extension
GIF规范允许在图像上渲染你指定文本.目前还没有什么常用应用程序能理解这个。IE, FireFox, 和Photoshop无法渲染这种类型的扩展。这种扩展标签值为01。暂不管
Application Extension
该规范允许将应用程序特定信息嵌入到GIF文件本身中。这种扩展标签值为FF。像GIF动画就是用到这种扩展。
卡通动画由动画师创造,他们画出一堆照片,每幅照片与上一张略有不同,当一个接一个地迅速显现时,就形成了动画片。 GIF图像中的动画以相同的方式实现。
比如下面的交通灯动画


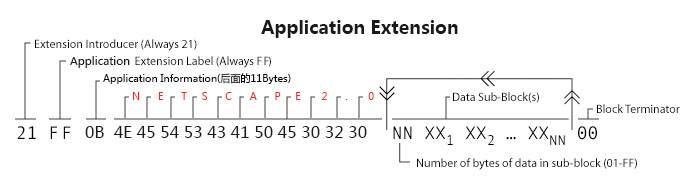
Application Extension中会记录动画的重复次数,来看下Application Extension中的数据
前三个字节 0x21 0xFF 0x0B,其中0xFF代表是一个Application Extension, 而0x0B代表后面有一个11个字节长的固定数据,它的值的ASCII值是”NETSCAPE2.0″
实际的”application data”存储在sub-blocks中.有两个值存储在存储在sub-blocks中. 第一个值总是01.然后 we have a value in the unsigned (lo-hi 字节) 格式来说明动画的重复播放次数.上图的值是0,它代表永久循环.
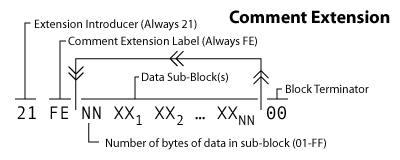
Comment Extension
你可以在GIF文件中嵌入注释。也许这将是一个有趣的方式来传递秘密信息。这种扩展标签值为FE。
Trailer
Trailer block预示着文件末尾,它是值总是3B
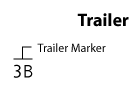
gifdecode.js
https://github.com/markbuild/gifdecode.js
Reference
https://www.w3.org/Graphics/GIF/spec-gif89a.txt
http://www.matthewflickinger.com/lab/whatsinagif/bits_and_bytes.asp