
本文介绍Linux运行命令时进程中的数据流、文件描述符的映射、管线管道、数据流向的控制。 Unix 的设计是非常强大的,不仅可以将一些小程序链接在一起以创建更大的程序,还可以将数据加载到管线中并将数据输出到文件中以备使用。
与Unix 关联的建模文件与文本数据流
默认情况下,Unix 将输入与键盘⌨️ 相关联,输出与显示器🖥 相关联。Unix 以将计算机中几乎所有东西(包括键盘⌨️ 和显示器🖥)都建模为文件📄而闻名。
写入显示器🖥 实际上只是写入到管理屏幕🖥 数据显示的文件📄。
从键盘读取数据就是从代表键盘⌨️的文件📄 中读取数据。
🖨️━📄━┓┏━📄━💾
⌨️━📄━ Unix ━📄━🖥
🌐━📄━┛┗━📄━ …
在Unix 世界,输入和输出称为进出进程的文本数据流。
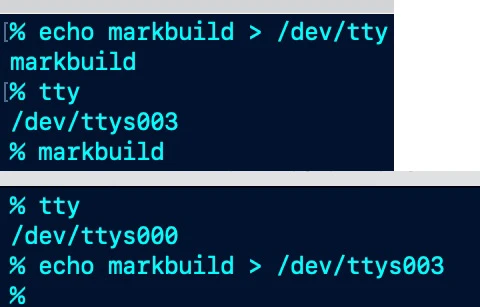
TTY
/dev/tty 是一个特别的文件,代表当前进程的终端,所以当你执行echo markbuild > /dev/tty, 你当前终端的屏幕上会显示 “markbuild”,另外 tty 命令会显示当前的终端设备。
文件流的文件描述符(File Descriptors)
有三种默认的输入/输出 (I/O) 流:标准输入 (stdin)、标准输出 (stdout)和标准错误 (stderr)。
默认情况下,这些流每个都有一个特定的文件描述符。文件描述符是一个与所打开文件相关联的整数,进程使用文件描述符来处理数据。三个默认流具有以下文件描述符编号:stdin = 0、stdout = 1 和 stderr = 2。
文件描述符存储在文件描述符表中,每个进程都有自己的文件描述符表(在创建进程时,默认情况下会创建 0、1 和 2 并将其映射到相应的流)。
| 进程A | 文件描述符表A | 0 ◀━stdin━ ⌨️ 1 ━stdout━▶ 🖥 2 ━stderr━▶ 🖥 |
| 进程B | 文件描述符表B | 0 ◀━stdin━ ⌨️ 1 ━stdout━▶ 🖥 2 ━stderr━▶ 🖥 |
| 进程… | 文件描述符表… | 0 ◀━stdin━ ⌨️ 1 ━stdout━▶ 🖥 2 ━stderr━▶ 🖥 3 ━stdout━▶ /path/myfile 📄 |
除了 0、1 和 2 之外,进程还根据需要使用其他文件描述符。分配新的文件描述符时,始终使用最低的未使用(未打开)文件描述符。因此,文件描述符 3 通常在默认设置 0、1 和 2 后首先使用。
数据流(Data Flow)
为执行命令创建的进程需要知道要将哪些数据(如果有)作为输入以及将哪些数据作为输出。

上图表示: 键盘⌨️将数据传递给运行命令的程序(从命令的角度来看,它通过 stdin 接收输入),并且该程序通过 stdout 将输出发送到终端🖥。
进程的文件描述符表将stdin 映射到键盘⌨️数据文件,stdout 映射到屏幕🖥数据文件。
实际上有两个流可以将输出写入终端🖥:stdout 和 stderr。比如在终端中的输入ls dir_x 命令来列出不存在的目录 dir_x 的内容
$ ls dir_x
ls: cannot access dir_x: No such file or directory显示第二行的流实际上是 stderr,而不是 stdout。

输入和输出的含义
一些命令会读取输入,这里输入的真正含义是什么呢?站在Shell 的角度(Shell 处理输入到终端上的命令行),在键盘⌨️上输入的内容是一般意义上的输入,Shell 专门处理
输入和命令所需要的输出,以便于运行命令的进程在文件(包括键盘⌨️和显示器🖥)之间传输数据。作为可选的命令参数实际上是从命令行读入的(作为参数数组);
而实际输入是从文件描述符映射的文件中读取的。因此可以将命令的 输入定义为使用 stdin(或可从中读取的重新调整用途的文件描述符)专门传入的数据,无论它是通过键盘输入,还是通过 I/O 重定向,或是作为文件参数传递给命令的数据(相对于选项参数,比如-r、-f)。当文件作为参数传递,如果进程将实际读取或操作该文件的内容(例如对内容进行排序,sort words.txt),那么可以认为它是输入,否则就不是(例如移动或重命名它,mv 1.txt dir/2.txt)。
为了说明一个可以没有输入但有输出的命令,可以看ls,它列出了当前目录中的所有文件。
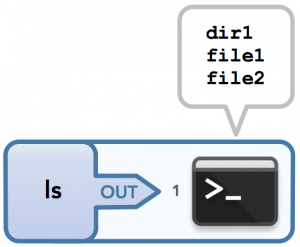
我们再看一个命令,如果一切正常,它不接受输入也不给出输出:mv,它可用于移动或重命名文件。由于没有以任何方式读取或使用此文件的内容,因此传入的文件不被视为输入。

如果我错误地使用mv导致发生错误,那么我将输出到 stderr:
$ mv
mv: missing file operand
Try 'mv --help' for more information.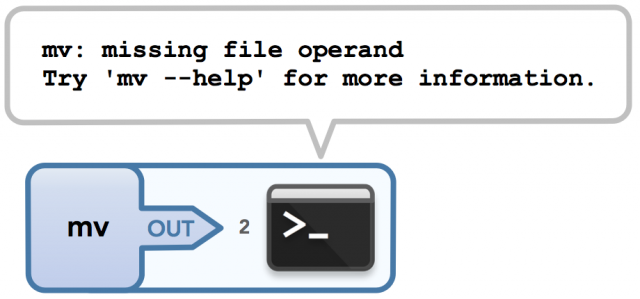
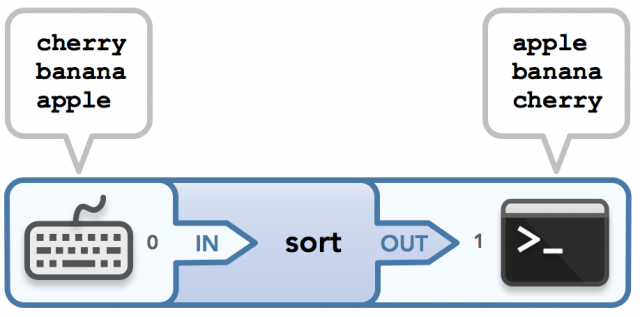
接下来是sort命令,在不使用文件参数和输入重定向的情况下使用时,终端等待用户输入要排序的字符串(每行一个字符串)。一旦用户键入 Ctrl-D(将关闭键盘与sort 进程通信通道写入端stdin 的连接),运行sort 命令的进程将知道所有需要的字符串都已输入。这些字符串通过 stdin 传递到运行命令,按所述进程排序,然后通过 stdout 写入终端。这是示例输入/输出:
$ sort
cherry
banana
apple
<Ctrl-D>apple
banana
cherry粗体字符串是用户输入,后面的字符串代表排序后的输出。
sort还可以使用文件名参数从指定文件中获取输入,而不是等待用户输入数据(例如,sort words.txt),这遵循我们对输入的定义,因为它是一个文件而不是一个选项参数(如sort -r)。
上面介绍的是数据从 stdin 到 stdout 或 stderr 的总体思路,接下来介绍如何控制输入和输出的流向。两种方法:使用管子,它允许一个进程的输出作为输入传递到另一个进程;使用 I/O 重定向,它允许文件作为数据的源和目标,而不是默认键盘和终端。
管子(Pipe)
Unix 有一个简单而有价值的设计理念,正如 Unix 管子的发明者 Doug McIlroy 所解释的那样:
“编写只做一件事并把它做好的程序。
编写能协同工作的程序。
编写能处理文本流的程序,因为这是一个通用的接口。”
管子的概念非常强大。管子允许将数据从一个进程传递到另一个进程(通过单向数据流),以便命令可以通过它们的流链接在一起。这样可以支持命令协同工作以实现更大的目标。
进程之间的链接可通过管线(pipeline)来表示: 管线上的命令通过管子连接,进程间的共享数据是通过一个管子未端流到另一个的。由于管线上的每个命令都在一个单独的进程中运行,每个进程都有一个单独的内存空间,我们需要一种方法来允许这些进程相互通信。这正是pipe() 系统调用能提供的能力 。
在实现方面,管子实际上只是与两个文件描述符相关联的缓冲流,这两个文件描述符设置为第一个可以读取第二个写入的数据。具体来说,在为处理管线上命令执行而编写的代码中,创建了一个包含两个整数的数组,和一个pipe()调用使用两个可用的文件描述符填充该数组,使得数组中的第一个文件描述符可以读入第二个文件描述符写入的数据。
真实的管子是这种抽象很好的类比。我们可以将一个过程中开始的数据流想象成一个孤立环境中的水,而让水流到下一个进程的环境中的唯一方法是用管子将环境连接起来。通过这种方式,水(数据)从第一个环境(进程)流入管子,将管子中的所有水填满,然后将水排放到另一个环境中。

比如命令 sort | grep ea:
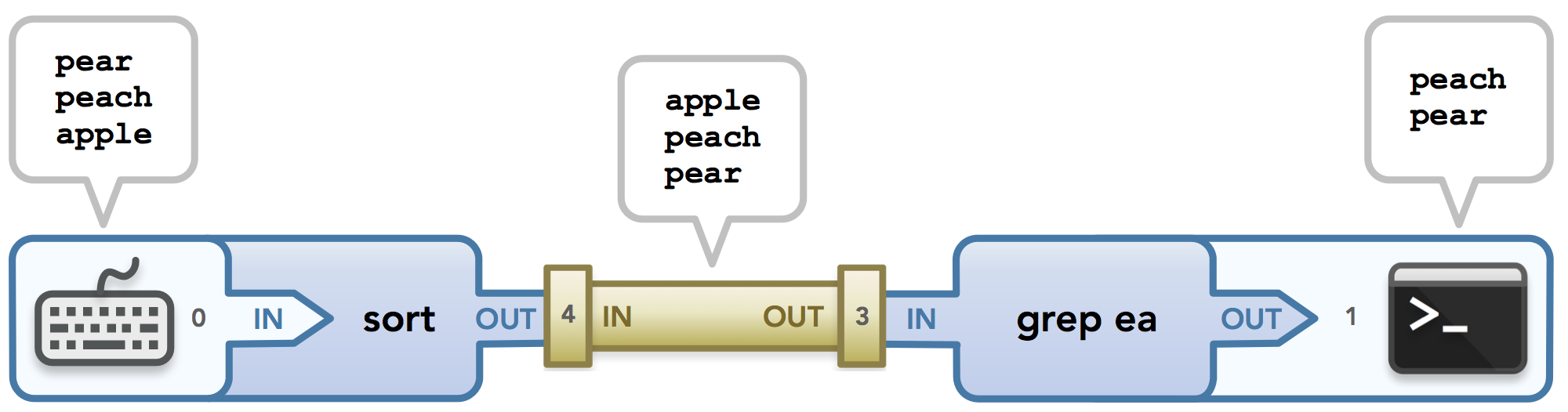
我们一点一点地分解它。sort命令,通过stdin(文件描述符0)等待用户的输入(如三个要排序字符串需)。接下来,字符串被排序并通过 stdout 作为输出发送,stdout 被送入管子。stdout 可以允许将数据发送到管子的左端(文件描述符 4)而不是终端屏幕。
这里有一个重要的细节:由于管线上的每个命令都在单独的进程中运行,因此每个命令都有自己的文件描述符版本,包括自己的 stdin、stdout 和 stderr。这意味着图中左侧显示的 0 属于运行sort 的进程,因此与右侧运行grep 的进程显示的 1 属于不同的文件描述符表。即使如此,由于流被设置为在进程边界之外发送数据,最终结果是,只要数据正确地沿管线向下传递,数据就会最终到达它所属的地方。
现在 sort 命令有一个已排序的字符串列表作为输出,它必须通过创建的管子将数据传递给下一个进程grep。数据流从sort 进程出来 并 进入管子,然后从管子中出来并进入grep进程。
现在可以讨论由pipe()调用分发的文件描述符 。假设在管线上执行命令的代码中, pipe()调用填充了一个文件描述符数组 {3, 4},这样写入 4 的数据可以被 3 读取。这些数字是什么实际上并不重要,甚至它们的顺序是递增的。给定的值只对进程重要,但文件描述符的目的对数据很重要!
数据被传递到管子,在接收到所有数据之前,它一直驻留在管子中,这样它就可以将自己排出到grep进程中。运行grep的进程搜索它接收的从管子输出的输入,以查找包含“ea”的行。然后它使用它的 stdout 流将匹配的字符串输出到终端🖥。全部完成!
在管线上运行命令
从前面我们知道管子用于将数据从一个命令的进程传递到另一个命令的进程,但还没有讨论运行这些命令的进程的层次结构。我们学会了编写程序,使得每个命令都在子进程中执行,而不是在父进程(调用进程)中执行。通常,父进程执行一切所需的设置,然后通过fork()调用创建子进程,并会建立父进程内存状态和文件描述符的克隆。因此,子进程最终拥有在调用fork()时父进程中存在的变量和文件描述符的独立副本。在fork()调用之后,对父进程的更改对子进程将不可见,反之亦然。
这种 children-execute-commands 模式对于执行单个命令似乎是不必要的,因为我们可以简单地在父进程中运行该命令而不需要创建子进程,但是当要考虑如何让代码足够通用以同时适用于单个命令和管线上的多个命令时,那么总是让不同的子进程执行每个命令是有价值的。这条规则也有例外,例如运行一个可以简单地在父进程中运行的内置命令(built-in),但在本次讨论中,我们就假设所有命令都在子进程中运行。
我们看一个运行sort 命令的C 语言示例。在这个示例中,输入通过dprintf() 直接打印到文件描述符, 以展示使用管子将数据从父进程发送到子进程的情况。
#include <unistd.h>
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
int fds[2]; // 一个包含两个文件描述符的数组
pipe(fds); // 用两个文件描述符填充数组 fds
pid_t pid = fork(); // 创建从父进程克隆的子进程
if (pid == 0) { // 如果 pid == 0, 那么这是一个子进程
dup2(fds[0], STDIN_FILENO); // fds[0] (管子的读取端)将其数据传给文件描述符 0
close(fds[0]); // 子进程不再需要文件描述符,因为标准输入是一个副本
close(fds[1]); // 子进程中未使用的文件描述符
char *argv[] = {(char *)"sort", NULL}; // 创建参数向量
if (execvp(argv[0], argv) < 0) exit(0); // 执行 sort 命令 (如果出现问题退出)
}
// 如果到达这里,表示我们在父进程中
close(fds[0]); // 父进程中未使用的文件描述符
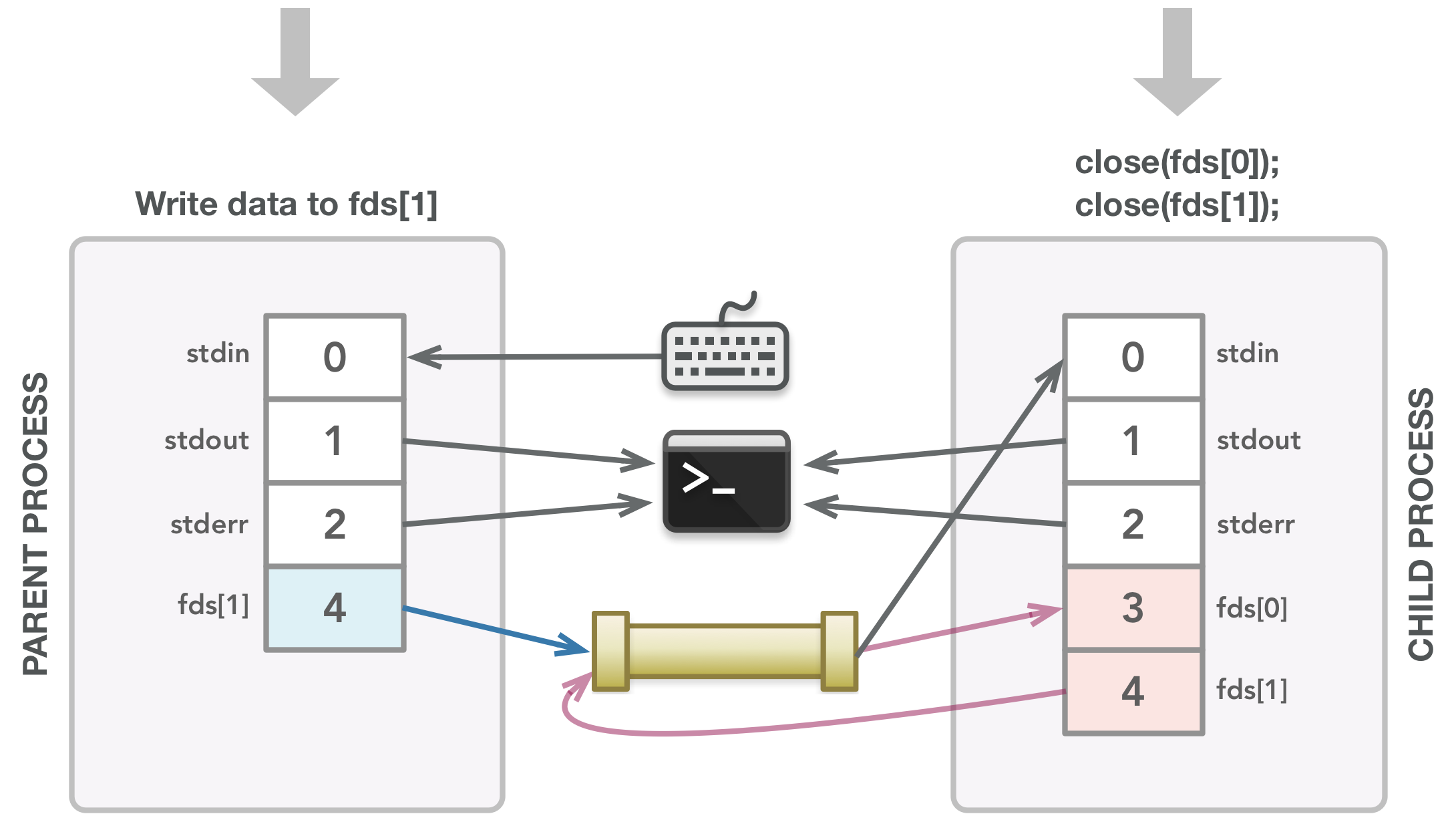
const char *words[] = {"pear", "peach", "apple"}; // 将输入写入可写的文件描述符,以便它可以从子进程读入:
size_t numwords = sizeof(words)/sizeof(words[0]);
for (size_t i = 0; i < numwords; i++) {
dprintf(fds[1], "%s\n", words[i]);
}
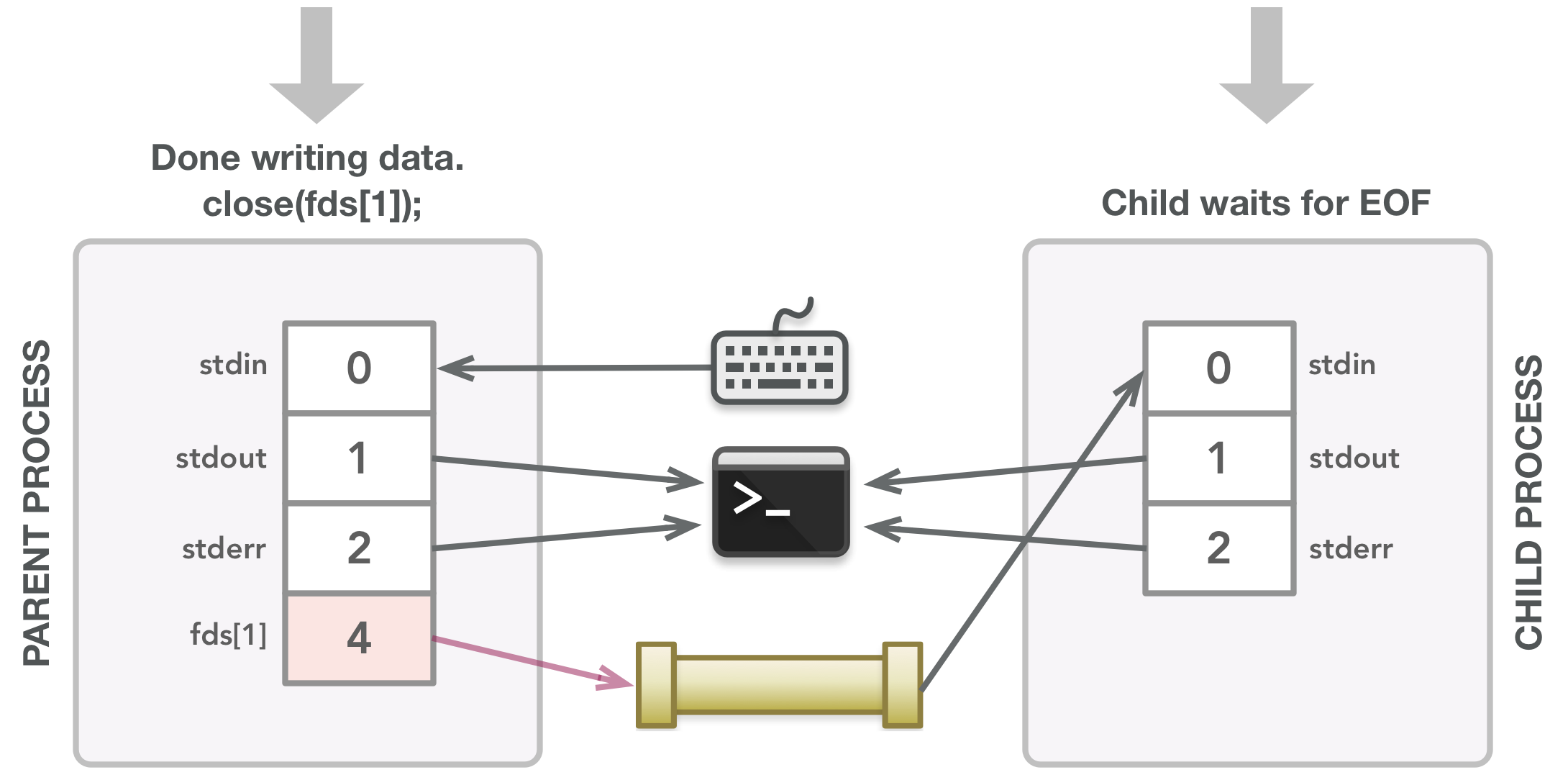
// 发送 EOF 以便子进程可以继续(子进程阻塞,直到所有输入都被处理):
close(fds[1]);
int status;
pid_t wpid = waitpid(pid, &status, 0); // 在退出之前等待子进程完成
return wpid == pid && WIFEXITED(status) ? WEXITSTATUS(status) : -1;
}写这个程序是为了运行一个特定的命令:sort。下面是代码的工作原理:在父进程中,创建一个数组来存储两个文件描述符。在pipe()调用之后,数组填充有连接的文件描述符,其中第一个将从子进程读取,第二个将由父进程写入。然后调用fork()来创建子进程,该子进程具有父进程的文件描述符和内存的副本。然后检查是否在子进程中运行。如果是,则子进程调用dup2()使其 stdin 将自身与管子的可读端相关联,这对应于 fds[0]。dup2()的一个重要细节工作是它会首先关闭它的第二个参数,如果需要的话,它是一个文件描述符。因此在这个例子中,stdin(默认情况下是打开的)首先关闭,这将删除它对默认键盘文件的引用。然后子进程的标准输入将能够通过 fds[0] 而不是从键盘接收数据。这就是dup2()的神奇之处!
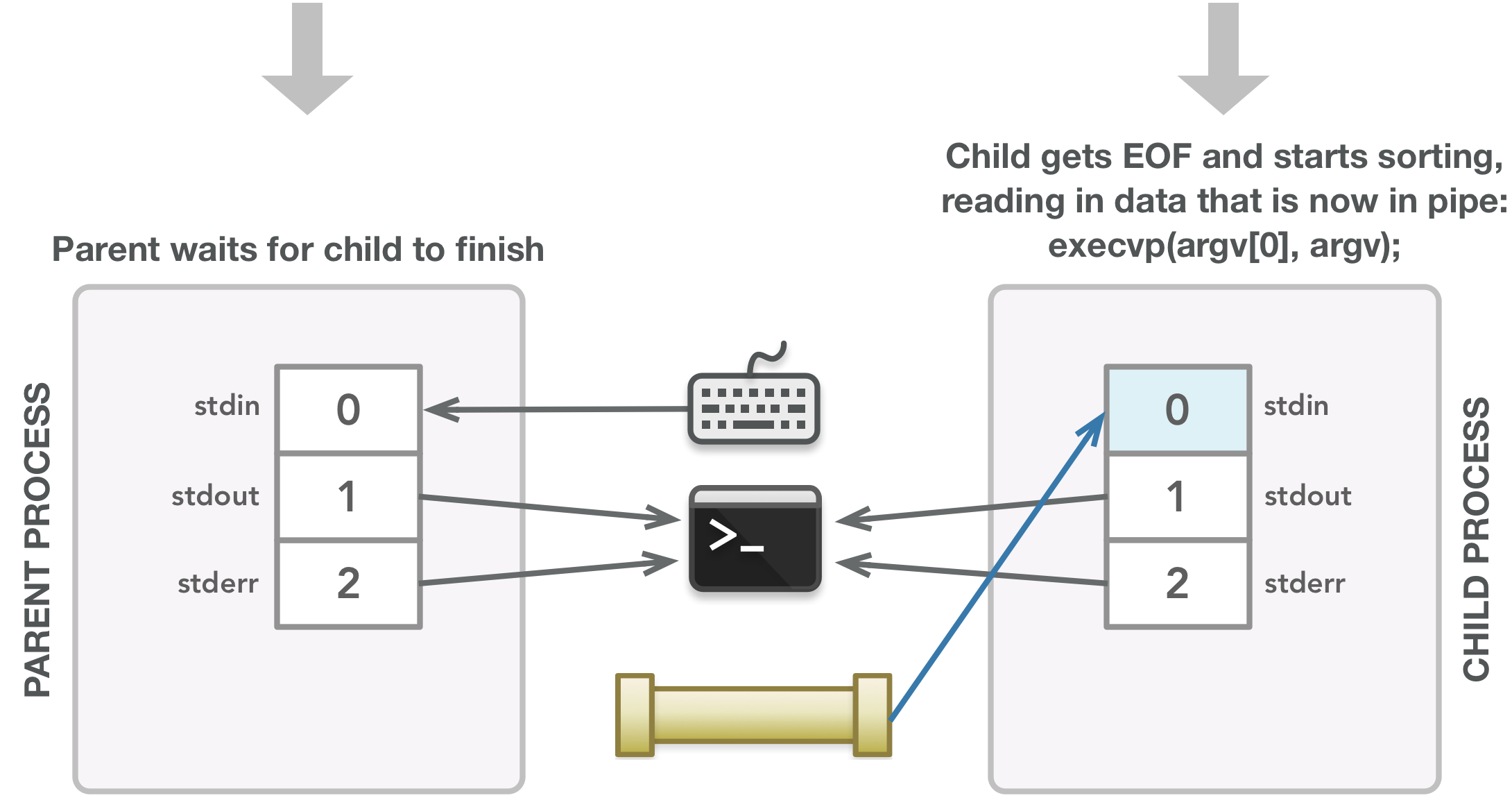
现在子进程的标准输入已准备好读入数据,子进程关闭由pipe()调用创建的文件描述符,因为它们在子进程中不再需要。然后子进程执行 sort 命令,在对数据进行排序之前会等待所有父进程的数据写入管子的适当端。
当调用fork()时,子进程可能会在父进程继续之前开始运行,在这种情况下,子进程会挂起,直到它接收到所有输入。一旦 sort 命令完成,子进程就会在execvp()调用(执行给定命令)之后完成并自动关闭其默认文件描述符 0、1 和 2。在fork() 之后创建子进程的调用,父进程关闭 fds[0],因为父进程不需要它(父进程只需要写入数据,而不是读取数据)。然后父级将给定数组中的每个单词写入管子的可写端 (fds[1]),在末尾添加一个新行字符以允许 sort 命令正确接收新行上的每个单词。当所有单词都写完后,父节点关闭 fds[1],因为它完成了写入数据,它会向子节点发送一个 EOF 以允许它执行排序命令。在退出之前,父进程负责等待子进程完成(通过waitpid()调用)。最后一行只是一种返回值的整洁方式,该值取决于事情是否按预期进行。
总之,这是整个事件序列的数据流向图:
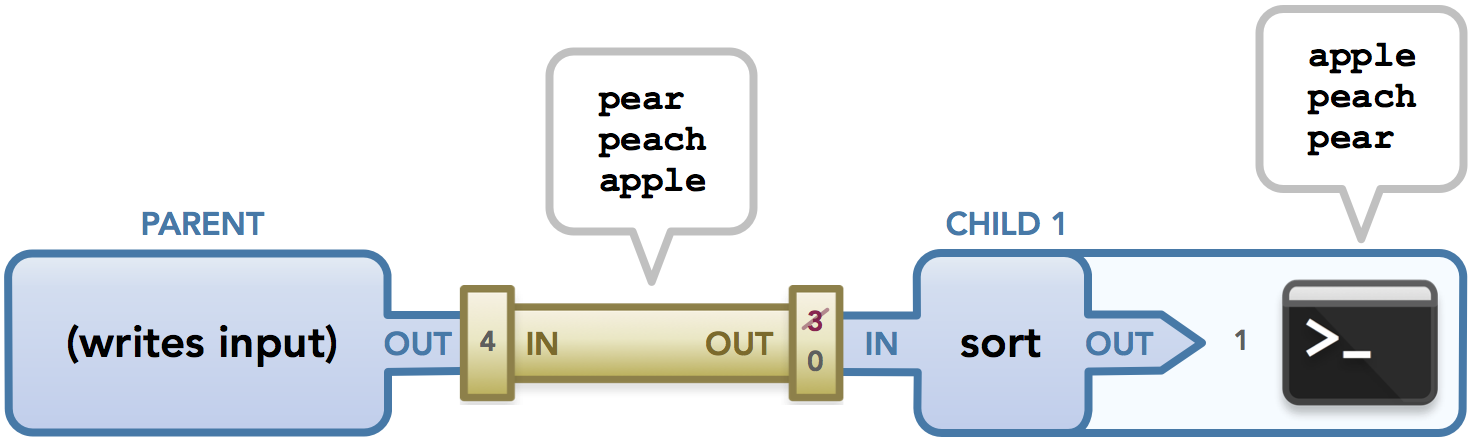
这是显示如何使用管子的示例,但在某种情况下不需要管子,例如,子进程可以简单地从默认stdin 访问数据,而不会受到父进程的任何干扰,这不需要使用管子。这段代码简单地展示了管子是如何建立从一个进程到另一个进程的通信,这种模式在管理具有多个命令的管线时是至关重要的。
为了了解这段代码中发生了什么,可看以下图表。在下图中,这些行显示了文件描述符与其指向的打开文件之间的关联。线箭头方向表示数据流向。这些图应该能够清楚地表明父子进程需要哪些文件描述符,这反过来应该有助于解释什么时候关闭文件描述符以避免泄漏。还要记住,由于不能保证父级中的指令在子级中的指令之前运行,下面的一些步骤可能会在不同的时间发生。这些图像只是为了让您了解执行过程中可能发生的情况,即使在此过程中可以交换几个步骤。

箭头表示数据流:stdin 从键盘接收输入,stdout 和 stderr 将输出发送到终端显示器。
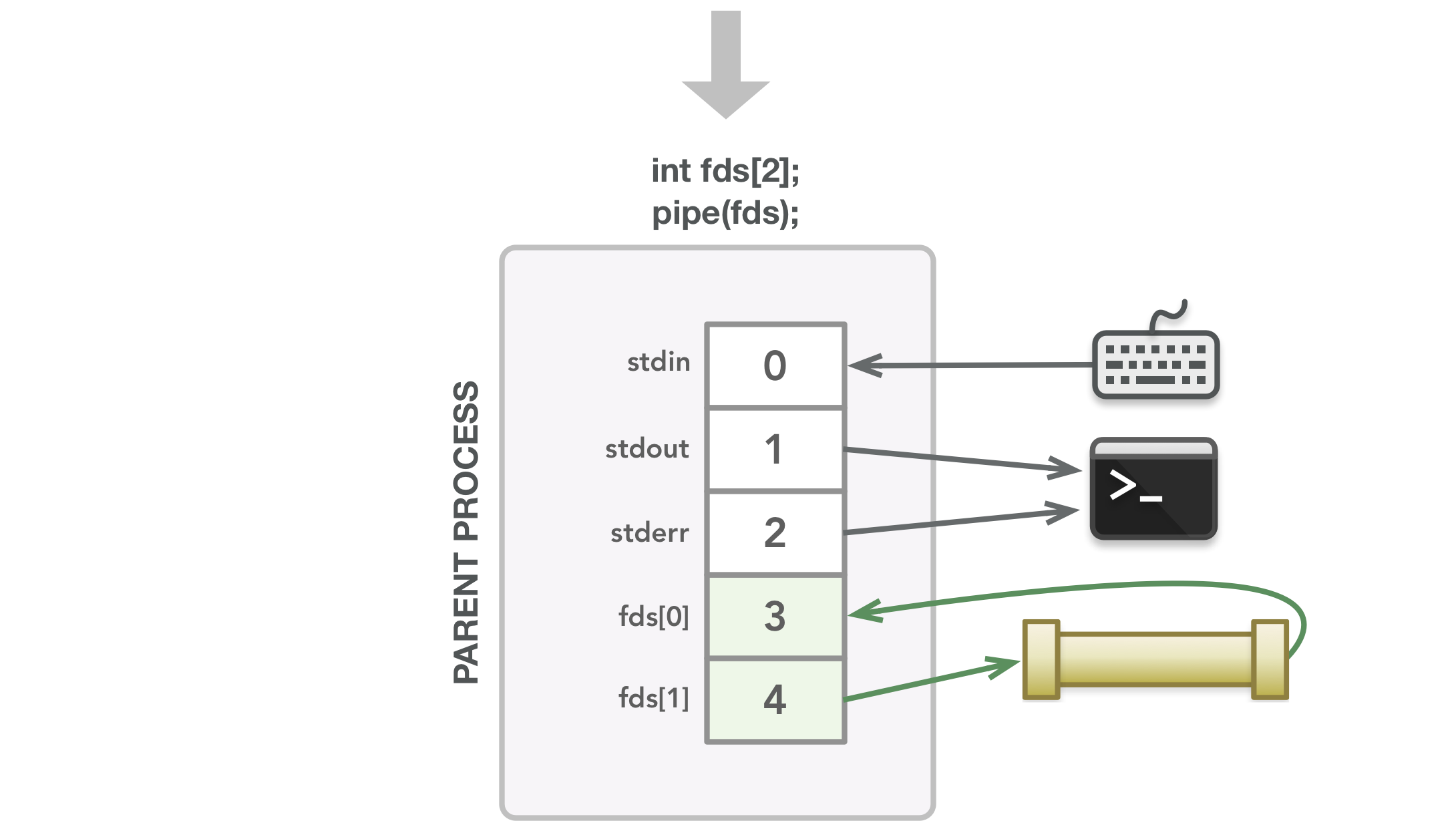
在这种情况下,进程可以通过 3 读取并通过 4 写入。
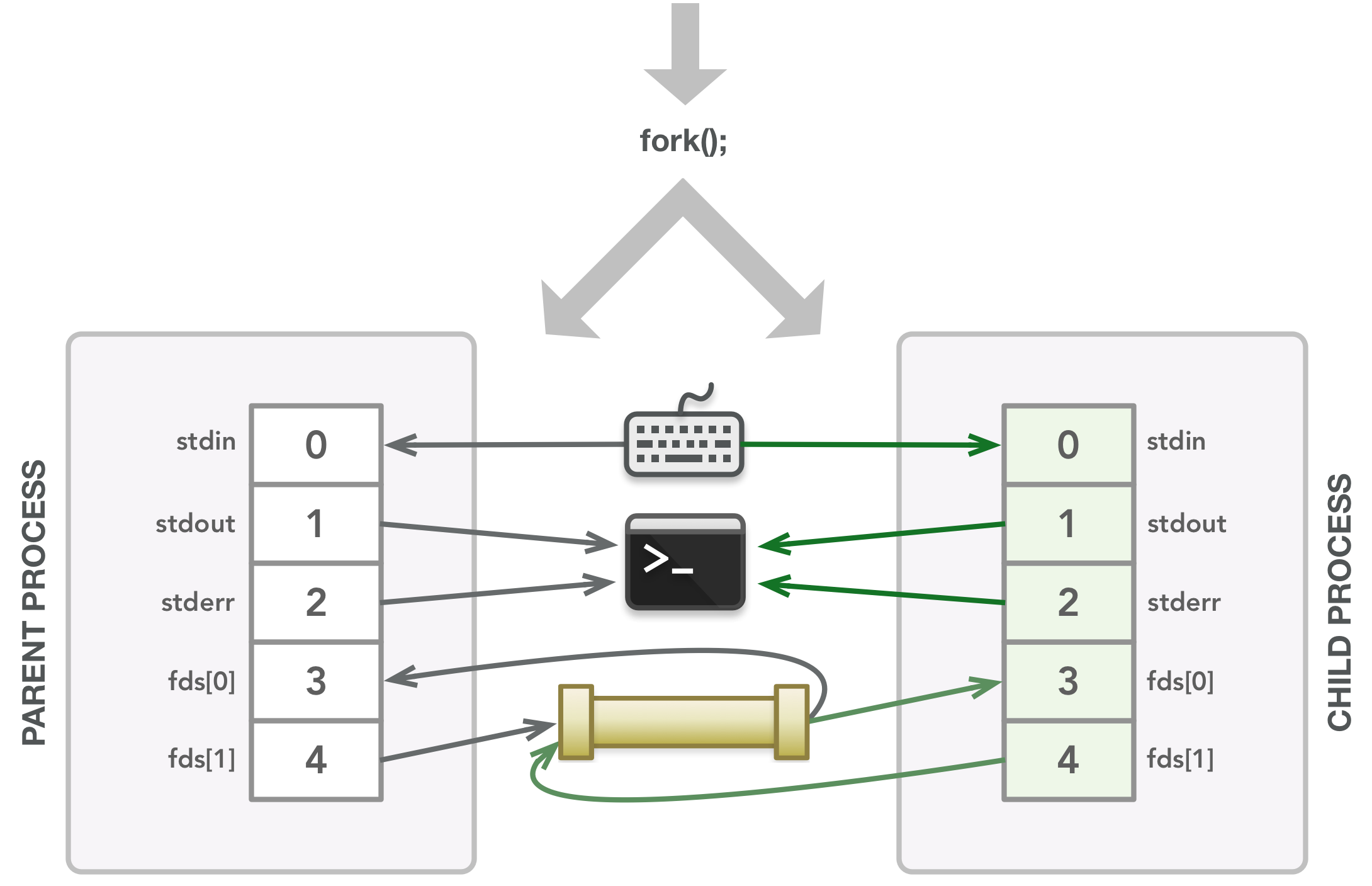
无论父进程文件描述符与哪个文件相关联,都与子进程文件描述符相关联的文件相同。
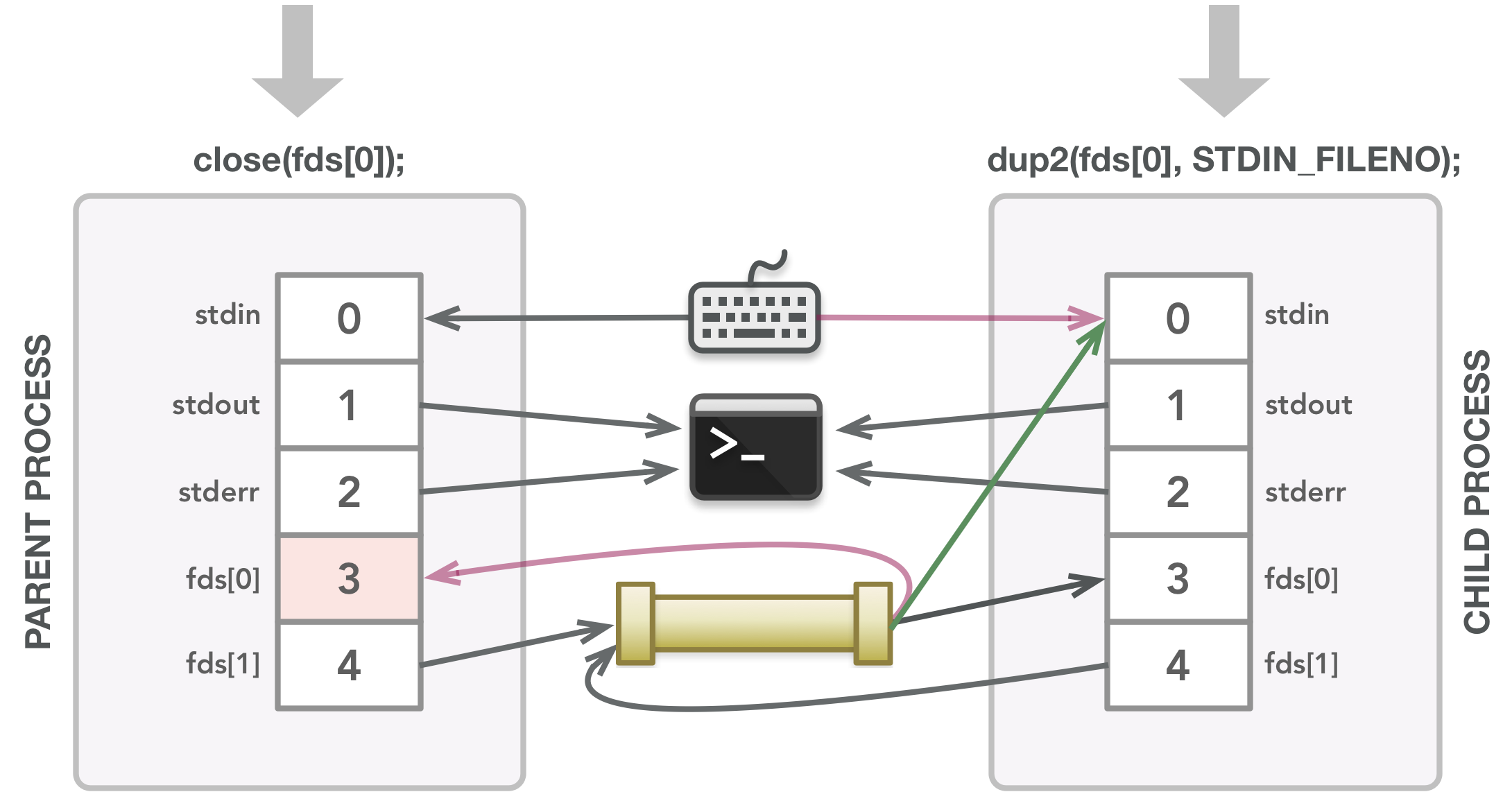
子进程调用 dup2() 使它的 stdin 成为 fds[0] 的副本,首先关闭文件描述符 0。
子进程关闭它不需要的文件描述符。
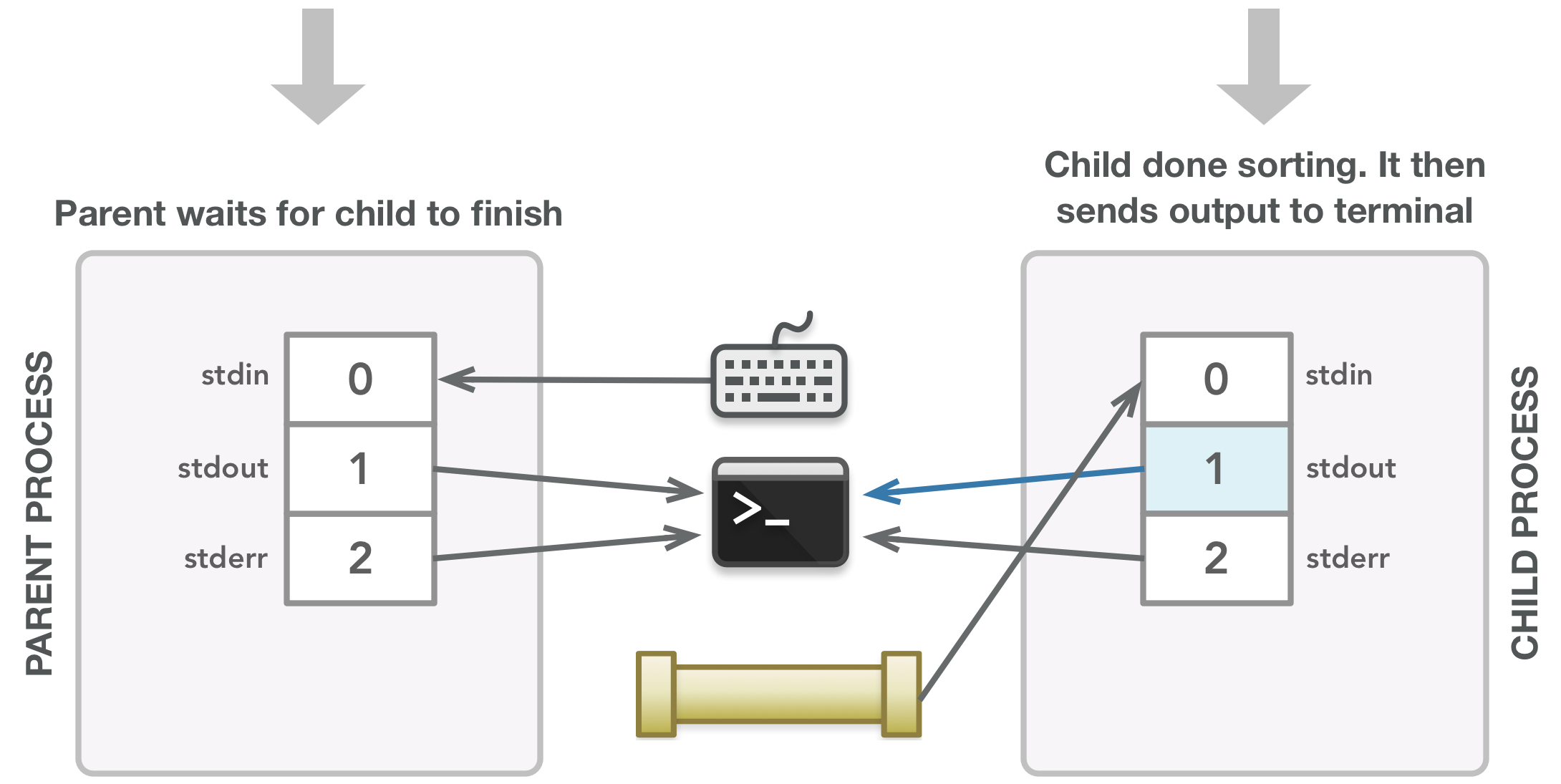
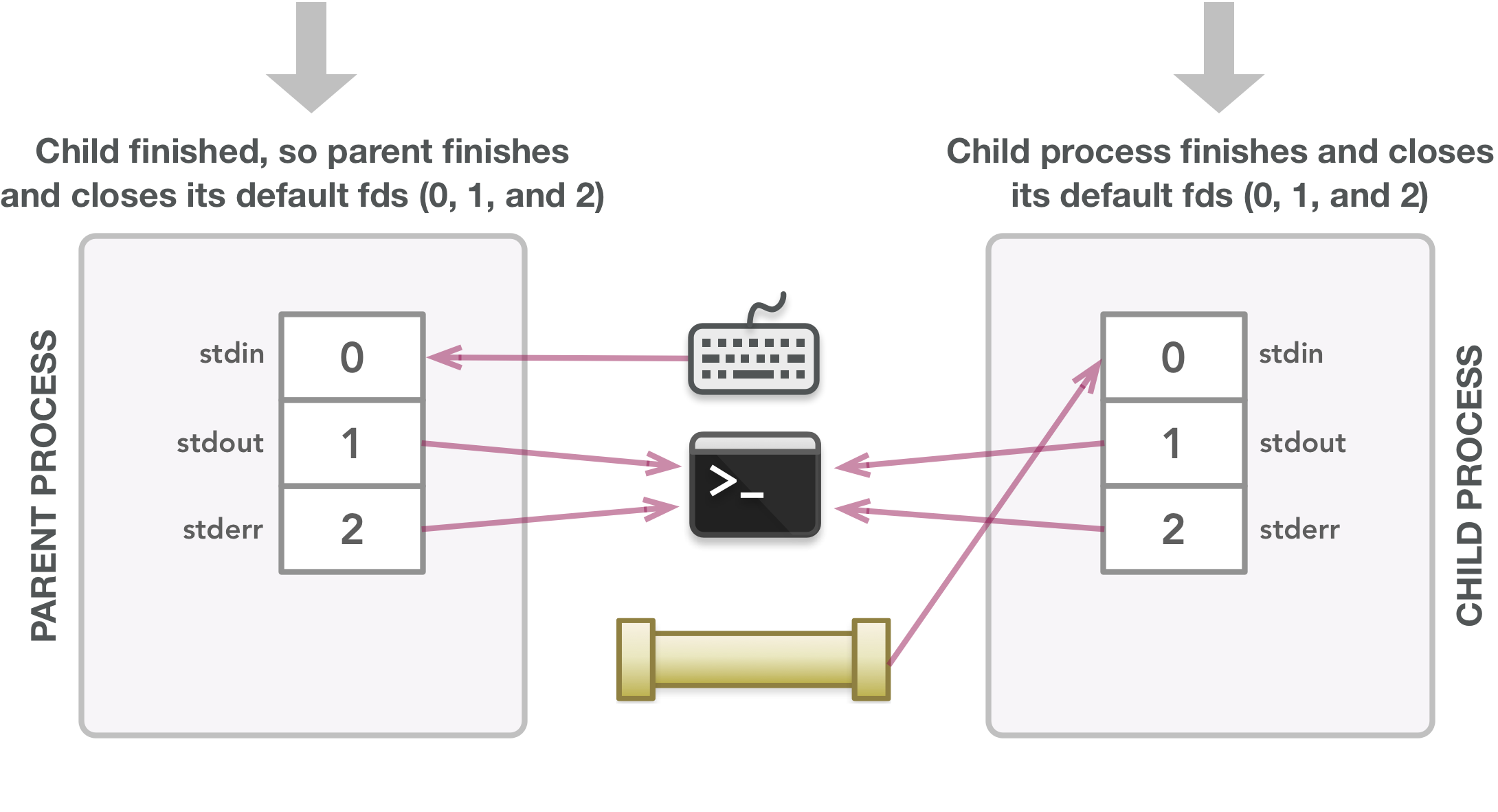
程序执行期间使用的所有文件描述符都已正确关闭。
在这里会注意到一件事,管子开始的文件描述符可能会根据需要重定向到另一个流。管子是一种便利,它为您提供了两个设置为一起工作的文件描述符,但它们的用途可以根据需要重定向,以确保数据流入和流出到正确的位置。
输入/输出重定向
如果想将文件作为管线上第一个命令的输入而不是用键盘进行输入,或想将管线上最后一个命令的输出发送到文件,这该怎么解决?可以通过 I/O 重定向来完成!
在命令行中,“<”字符用于输入重定向,“>”用于输出重定向,如果输出文件不存在则创建输出文件,如果已经存在则覆盖。要将数据追加到输出文件尾部而不是覆盖内容,可以使用“>>”。
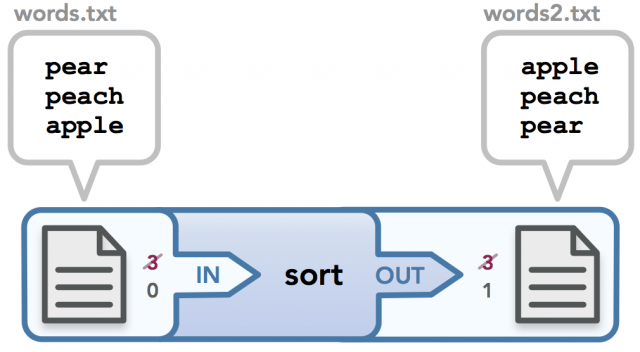
看一个同时使用输入和输出重定向的示例。假设我们有文件words.txt包含以下内容:
$ cat words.txt
pear
peach
apple我们可以使用这个文件作为sort命令的输入,然后将内容输出到另一个文件(如有需要,输入输出也可以是同一个文件),如下所示:
$ < words.txt sort > words2.txt
$ sort < words.txt > words2.txt //另一种写法屏幕上没有输出,因为输出存储在words2.txt 中。如果使用cat打印输出文件的内容,会得到以下内容:
$ cat words2.txt
apple
peach
pear实现 I/O 重定向相对简单。可以简单地使用之前看到的dup2()魔法:
// if first command in pipeline has input redirection
if (hasInputFile && is1stCommand) {
int fdin = open(inputFile, O_RDONLY, 0644);
dup2(fdin, STDIN_FILENO);
close(fdin);
}
// if last command in pipeline has output redirection
if (hasOutputFile && isLastCommand) {
int fdout = open(outputFile, O_WRONLY | O_CREAT | O_TRUNC, 0644);
dup2(fdout, STDOUT_FILENO);
close(fdout);
}管线上第一个命令(is1stCommand)如果有需要重定向的输入(hasInputFile),则对文件调用open()并将该数据流分配给open()使用的文件描述符。然后使用dup2()魔法允许stdin 读取该文件的内容作为输入。同样,如果在管线的末尾(isLastCommand)需要输出重定向(hasOutputFile),则重定向 stdout 以将最后一个命令的内容写入指定文件。
这是代表上一个示例的图表:
您可能想知道为什么文件描述符都以 3 开头。我在自己编写的mini-shell中运行此命令,因此我能够打印出运行任何命令时分配的文件描述符。我的 shell 使用上面显示的代码。请注意,首先我检查是否有输入重定向。如果有,我调用open()命令读取数据,该命令将这个流分配给文件描述符 3。一旦重定向 stdin 来处理 3 处理的数据,然后关闭 3,这使得 3 可用于输出重定向查看。因此,这两个文件一开始都使用 3,但随后被适当地重定向到需要数据的流,如红色删除线文本所示。
可见 Unix 的设计是非常强大的,不仅可以将一些小程序链接在一起以创建更大的程序,还可以将数据加载到管线中并将数据输出到文件中以备使用。这一切都是很牛逼的。
英文原文:http://www.rozmichelle.com/pipes-forks-dups/